在
半导体行业,没有比
FPGA更寡头的市场了,马太效应所建立的护城河让任何一个新玩家都面临着勇气的巨大考验。好在FPGA的竞争并不拒绝方法论角逐的机会,人们很容易在成功者昔日的道路上看到这样的轨迹——创新的
设计方法和商业模式。对于新玩家而言,这是一条近道。Achronix进入FPGA市场已经有几年了,除了交付FPGA芯片这种传统模式,向SOC公司提供嵌入式FPGA IP就是他们走“近道”的方法,而在他们最新推出的第四代eFPGA产品Speedcore Gen4 eFPGA IP时,除了TSMC 7nm工艺所产生的对标联想外,其在设计方法上也走了更多。
算力对硬件提出的要求
为
AI、
机器学习这类前沿应用提供
技术产品的公司都在面对这类问题:摩尔定律在减速的同时,通信网络带宽在急剧增加,边缘计算,数十亿计的物联网设备,意味着每秒数十亿到数万亿次的运算。传统云和企业数据中心计算资源和通信基础设施无法满足数据速率的指数级增长、快速变化的安全协议、以及许多新的网络和连接要求。传统的多核
CPU和SoC无法在没有辅助的情况下独立满足这些要求。算力的提升主要依靠针对特定应用和数据集的体系结构进行专门优化。未来的微处理器将包括几个特定于域的核,这些核仅能很好地执行某一类计算,但它们的性能明显优于通用核。

图:这张图显示了40年来计算性能要求的变化
Achronix 公司市场营销副总裁S
teve Mensor认为,不同应用对于计算的要求不同,如计算加速要求高能耗比,
5G则要求低功耗高性能的可
编程硬件,边缘计算要求最低功耗,计算存储需要低功耗低成本,网络加速和智能卡则需要用于CPU卸载的高速率加速器,而汽车驾驶则需要低成本和低功耗的硬件加速。“FPGA最适合AI/ML的这些多元应用场景,”Mensor说。“如果需要通用灵活性,CPU最合适,如果是专用场景,
ASIC最强,但它不可变,应用上不灵活。
GPU和FPGA是最适合AI计算应用的,相对而言,GPU更适合云端计算,FPGA则是边缘计算。”
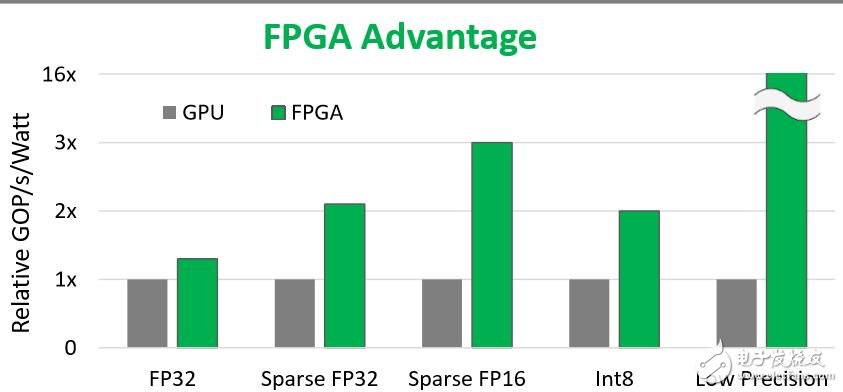
图:FPGA比GPU更具有功耗上的优势
新产品的设计方法
说回Achronix最新推出的第四代产品,该公司提供给
电子发烧友的
资料显示其较上一代产品性能提高了60%、功耗降低了50%、
芯片面积减少65%,同时保留了原有的Speedcore eFPGA IP的功能。该资料尤其提到了其在AI/ML的算力上提升了3倍。这主要源于Speedcore Gen4架构中,其资源逻辑库单元模块中加入了机器学习处理器(MLP)。作为一种高度灵活的计算引擎,MLP模块与存储器紧密
耦合,从而为AI/ ML应用提供了高能耗比和低成本的选择。值得注意的是,在不久前,Micron曾宣布他们最新的GDDR6存储器支持这款7nm工艺技术的FPGA芯片,并表示这个组合的成本能够比其他使用可比存储解决方案的FPGA低出一半。
这些性能是怎么提高的?总的来讲是三点:增强的逻辑单元、Speedcore下一代的路由结构、AI/ML专用的
DSP单元MLP。

图:这张图显示了增强的逻辑单元
不同于目前FPGA高性能总线专用路由架构,Speedcore下一代的路由结构把高性能专用总线分组路由的总线路由通道与标准路由通道分开,以确保无拥堵,同时,新架构优化了内存和MLP之间运行的总线,并创建巨型分布式运行时可配置交换网络。
 �
+�'.�Q-�
�
+�'.�Q-�
图:Speedcore下一代的路由结构
此外,该路由结构中还有专用的总线多路复用器,可满足更广泛的多路复用要求。“这种设计使得总线功能的性能提高了2倍,节省了LUT的资源,提高了综合资源利用率。这为高带宽和低延迟应用提供了很好的方案,并在业界首次实现了将网络优化应用于FPGA互连。”Mensor说道。
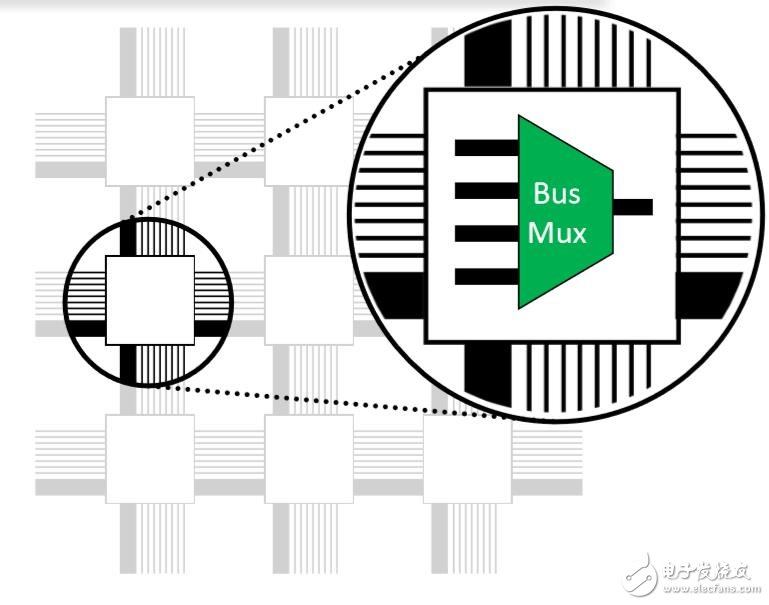
图:专用的总线多路复用器
MLP是一个完整的AI/ML计算引擎,每个MLP包括一个循环
寄存器文件(Cyclical Register File),它用来存储重用的权重或数据。各MLP与相邻的MLP单元模块和更大的存储单元模块紧密耦合,以提供最高的处理性能、每秒最高的操作次数和最低的功率分集。这些MLP支持各种定点和浮点格式,包括Bfloat16、16位、半精度、24位和单元块浮点。用户可以通过为其应用选择最佳精度来实现精度和性能的均衡。
F�|�Q#KwN� 
图:MLP块配置
为了补充MLP并提高AI/ML的计算密度,Speedcore Gen4 的LUT可以实现比任何独立FPGA芯片产品高出两倍的乘法器。领先的独立FPGA芯片在21个查找表可以中实现6x6乘法器,而Speedcore Gen4仅需在11个LUT中就可实现相同的功能,并可在1 GHz的速率上工作。

图:每个Speedcore都可完全按需定制
据悉,第四代Speedcore eFPGA 7nm IP 目前已可提供,交付周期是1个半月,16nm的则会2019年上半年提供。Mensor并没有解释为什么7nm工艺IP比16nm先提供,笔者分析这应该是基于客户需求的商业考虑,毕竟领先FPGA的工艺是7nm,而从先进工艺向后延展,是十分容易的。











