|
|
AI时代硬件领域犹如战国群雄争霸,没有一种芯片能完全通用,也没有一家公司能独霸市场。在这个激动人心的时代,硬件研发似乎有无限可能。从计算力的飞速提升促进人工智能第三次大爆发讲起,谢源回顾了计算力增长的两大因素——摩尔定律和硬件架构创新,并指出在摩尔定律放缓的当下,硬件架构创新对计算力的进一步提升将愈发重要。 +�� niz(]� 结合目前几种常见的芯片及其各自的适用场景和优势,谢源分析了未来硬件发展的三大趋势:①软硬结合,以谷歌、微软为代表的软件公司也开始自己开发硬件;②异构计算,在同一个平台上使用不同的芯片;以及③从通用向专用发展。 SJg4P�4|� 同时,AI时代的硬件架构创新还有一大难关——存储墙。谢源以谷歌TPU为例,结合AMD和英伟达的GPU发展路线图,介绍了各大公司使用3D堆叠内存技术,克服存储墙的问题。不仅如此,谢源还介绍了他和同事的最新研究项目,计算存储一体化,直接在内存上做计算。 "]1 !<M6\i 人类的大脑计算和存储不是分开的,不需要数据搬移,所以未来的计算机体系结构可能要改变传统的把计算和存储分开的冯·诺依曼架构。谢源的研究团队正在研究计算存储一体化,希望在未来五年能够从底层到高层打通。“我们把AI的ABC(算法+大数据+计算),又加上D(Domain knowledge)跟E(Ecosystem),探究计算存储一体化,希望能够使下一代AI芯片能够有更进一步的发展。” {O ]^8#�v^  v?Z30?_�&h 谢源:今天我要给大家讲的是《人工智能时代的计算机架构创新》。人工智能现在最主要的三大支柱,可以称之为AI的“ABC”——算法(Algorithm)、数据(Big data)、计算能力(Computing)。我今天主要讲计算能力,因为计算能力在AI的历史上发挥了非常大的作用。 xe��o5�)�� v?Z30?_�&h 谢源:今天我要给大家讲的是《人工智能时代的计算机架构创新》。人工智能现在最主要的三大支柱,可以称之为AI的“ABC”——算法(Algorithm)、数据(Big data)、计算能力(Computing)。我今天主要讲计算能力,因为计算能力在AI的历史上发挥了非常大的作用。 xe��o5�)�� 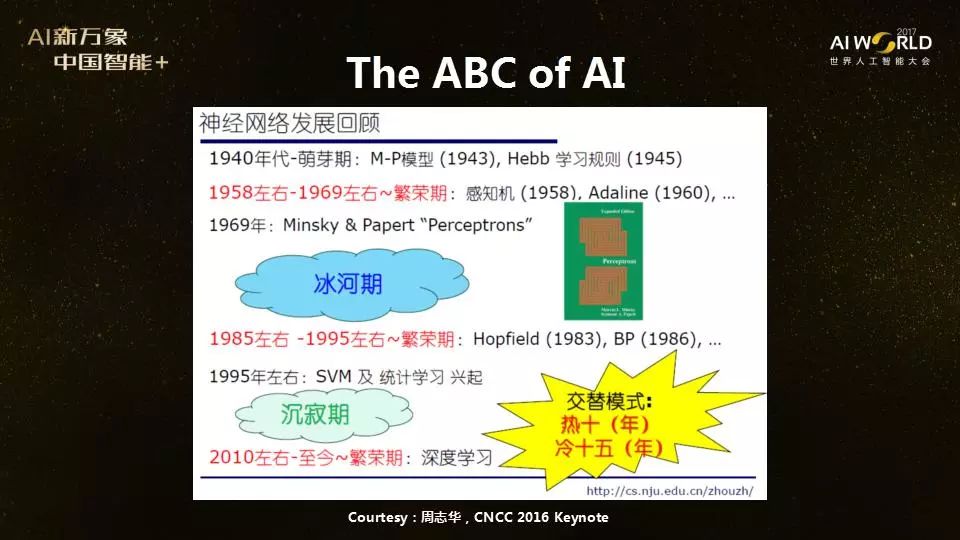 �N`3q54�_$ 去年,周志华教授在中国计算机大会上展示了这张图,他说人工智能的历史看起来很有意思,是以交替模式在发展,热10年,冷15年:1958-1969年左右是一个繁荣期,然后进入冰河期,1985-1995年之间又出现了一个繁荣期,再往后又进入沉寂期,最近再一次热起来。 ]_!5g3V�Qh 巧合的是,这几次人工智能的繁荣期,都跟计算能力的迅速增长有很大关系,比如第一次繁荣期,上世纪50年代时,电子计算机开始快速发展,第二次繁荣的80年代时则是像英特尔X86的处理器和内存条技术得到广泛应用。最近这次AI浪潮兴起很重要的一个原因,也是CPU、GPU集群的普及。 1�:!_AU��? 从CPU到GPU:吴恩达的例子,16000多个CPU三天到3个GPU两天 g�Egh�DO_G �N`3q54�_$ 去年,周志华教授在中国计算机大会上展示了这张图,他说人工智能的历史看起来很有意思,是以交替模式在发展,热10年,冷15年:1958-1969年左右是一个繁荣期,然后进入冰河期,1985-1995年之间又出现了一个繁荣期,再往后又进入沉寂期,最近再一次热起来。 ]_!5g3V�Qh 巧合的是,这几次人工智能的繁荣期,都跟计算能力的迅速增长有很大关系,比如第一次繁荣期,上世纪50年代时,电子计算机开始快速发展,第二次繁荣的80年代时则是像英特尔X86的处理器和内存条技术得到广泛应用。最近这次AI浪潮兴起很重要的一个原因,也是CPU、GPU集群的普及。 1�:!_AU��? 从CPU到GPU:吴恩达的例子,16000多个CPU三天到3个GPU两天 g�Egh�DO_G 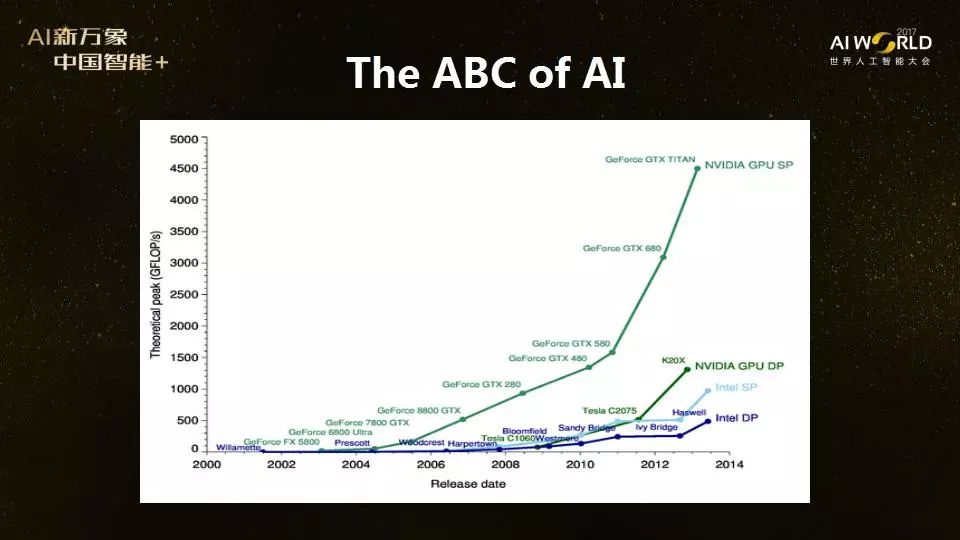 ���[D���r' 最近这十几年,GPU的计算能力发展尤其迅速,以NVIDIA 的GPU为例,从2002 - 2014年经历了飞速的增长(注:上图增长趋势最快的线条,计算速度理论峰值从小于500 GFLOPS/s 增长到超过4500 GFLOP/s)。 ?VUU[h8"v5 ���[D���r' 最近这十几年,GPU的计算能力发展尤其迅速,以NVIDIA 的GPU为例,从2002 - 2014年经历了飞速的增长(注:上图增长趋势最快的线条,计算速度理论峰值从小于500 GFLOPS/s 增长到超过4500 GFLOP/s)。 ?VUU[h8"v5  +ZFw3KEkz� +ZFw3KEkz�  _{�Q)�5ooP 这次深度学习热潮大概是从2012年左右开始的。很有意思的是,吴恩达在2012年的文章是在一个由1000台机器组成的Cluster上面做的,16000多个CPU用了三天时间训练。到了第二年,同样的事情,吴恩达在GPU上做,3个GPU两天时间就完成了。这充分说明了从CPU到GPU的计算能力变化给人工智能带来的驱动力。 9�9<]~,t=5 同时,AI的发展也大幅拉升了NVIDIA股价:NVIDIA在2012年的时候股价是11美元,现在已经是200多美元。 uD�he�
��) 如何提升计算能力?硬件架构创新将变得越来越重要 E�@}N}�SR� 回过头来看计算能力,既然计算力对AI应用非常重要,那我们怎样才能有更强的计算能力呢?总结起来无非两种,第一种是摩尔定律所带来的Technology Scaling,第二种就是计算机架构的创新。 oT7���6�)O _{�Q)�5ooP 这次深度学习热潮大概是从2012年左右开始的。很有意思的是,吴恩达在2012年的文章是在一个由1000台机器组成的Cluster上面做的,16000多个CPU用了三天时间训练。到了第二年,同样的事情,吴恩达在GPU上做,3个GPU两天时间就完成了。这充分说明了从CPU到GPU的计算能力变化给人工智能带来的驱动力。 9�9<]~,t=5 同时,AI的发展也大幅拉升了NVIDIA股价:NVIDIA在2012年的时候股价是11美元,现在已经是200多美元。 uD�he�
��) 如何提升计算能力?硬件架构创新将变得越来越重要 E�@}N}�SR� 回过头来看计算能力,既然计算力对AI应用非常重要,那我们怎样才能有更强的计算能力呢?总结起来无非两种,第一种是摩尔定律所带来的Technology Scaling,第二种就是计算机架构的创新。 oT7���6�)O 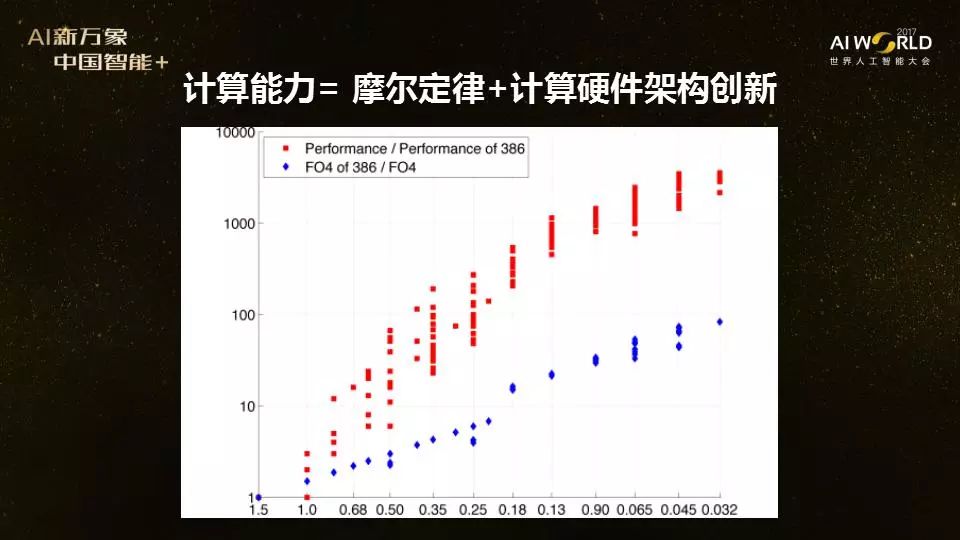 ;��a"g��<v 过去50年里,摩尔定律是处理器性能提高的关键因素。遵循摩尔定律,每隔两年左右,晶体管变得更小、更快,在同样面积的硅片上可以放下更多更快的晶体管。但是,光有工艺上的提高并不够。 c`�S`.WI�D 2012年,斯坦福大学研究小组做了个统计,收集了过去几十年几千款CPU的数据,比如他们统计的这张图上,蓝色这条线是英特尔80386 CPU性能提高的速度,如果不做任何架构上的创新,只是把晶体管做小,速度的确可以增长。但是,如果再加上架构上的创新(红线)(其余几千款CPU性能指标),就能够把CPU的性能进一步提高 [1]。 ,z4)A&F[c; 因此,摩尔定律非常重要,架构创新也非常重要,架构创新是计算能力增强的一个重要因素,这两者的结合使过去50年计算能力得到了飞速的增长。但是,现在出现了一个问题,摩尔定律开始变慢。按照现在半导体的路线图看,在2021年达到5纳米的制程后,我们还能不能继续往下走?这是一个大问号。在摩尔定律不断减缓甚至会停止的情况下,实际上架构的创新会对计算能力增长起到更大的作用。 ~q�u�o�f>� AI时代,硬件市场群雄争霸,软硬结合、异构计算、从通用到专用是三大趋势 6pJ�FrWe{ 刚刚说过,人工智能三大要素,算法、大数据和计算能力,我认为在第三次AI浪潮里面,计算能力起到了非常重要的作用。从我们做计算的角度看,未来一个很重要的趋势是软件和硬件相结合。 ����� |2<y 例如,我们看谷歌,现在谷歌不再是一家单纯的软件公司,大家也都知道,最近谷歌发布了TPU(注:Tensor Processing Unit,张量处理器),这是他们自己专用的硬件。过去我们认为微软是一家纯软件公司,但是今年微软发布了最新一代的HPU(注:Holographic Processing Unit,全息处理器,集成于微软的HoloLens中)。还有其他一些公司也在从事硬件方面的研发,更多这样的芯片产品出来,英文26个字母估计都要被用上。所以,我觉得未来的一大趋势是软件和硬件的融合。 +D�7>$&B�D ;��a"g��<v 过去50年里,摩尔定律是处理器性能提高的关键因素。遵循摩尔定律,每隔两年左右,晶体管变得更小、更快,在同样面积的硅片上可以放下更多更快的晶体管。但是,光有工艺上的提高并不够。 c`�S`.WI�D 2012年,斯坦福大学研究小组做了个统计,收集了过去几十年几千款CPU的数据,比如他们统计的这张图上,蓝色这条线是英特尔80386 CPU性能提高的速度,如果不做任何架构上的创新,只是把晶体管做小,速度的确可以增长。但是,如果再加上架构上的创新(红线)(其余几千款CPU性能指标),就能够把CPU的性能进一步提高 [1]。 ,z4)A&F[c; 因此,摩尔定律非常重要,架构创新也非常重要,架构创新是计算能力增强的一个重要因素,这两者的结合使过去50年计算能力得到了飞速的增长。但是,现在出现了一个问题,摩尔定律开始变慢。按照现在半导体的路线图看,在2021年达到5纳米的制程后,我们还能不能继续往下走?这是一个大问号。在摩尔定律不断减缓甚至会停止的情况下,实际上架构的创新会对计算能力增长起到更大的作用。 ~q�u�o�f>� AI时代,硬件市场群雄争霸,软硬结合、异构计算、从通用到专用是三大趋势 6pJ�FrWe{ 刚刚说过,人工智能三大要素,算法、大数据和计算能力,我认为在第三次AI浪潮里面,计算能力起到了非常重要的作用。从我们做计算的角度看,未来一个很重要的趋势是软件和硬件相结合。 ����� |2<y 例如,我们看谷歌,现在谷歌不再是一家单纯的软件公司,大家也都知道,最近谷歌发布了TPU(注:Tensor Processing Unit,张量处理器),这是他们自己专用的硬件。过去我们认为微软是一家纯软件公司,但是今年微软发布了最新一代的HPU(注:Holographic Processing Unit,全息处理器,集成于微软的HoloLens中)。还有其他一些公司也在从事硬件方面的研发,更多这样的芯片产品出来,英文26个字母估计都要被用上。所以,我觉得未来的一大趋势是软件和硬件的融合。 +D�7>$&B�D  WC�&�V9�Yk AI时代的硬件创新非常激动人心,这是一个战国群雄争霸的时代,没有一个完全通用的芯片,也没有一家公司可以统治整个市场。 5�;WE�S�k� 上面这张图展示了目前在AI时代硬件的各种解决方案。取决于应用场景,数据类型,还有资源的限制,每种硬件方案有自己各自的优势,还没有哪种方案可以一统天下。比如说谷歌的TPU,第一代做推理(inference),第二代做推理(inference)和训练(training)都是在云端做。而FPGA 或者是一些专用芯片,则可能更适合在功耗受限的端来做。 �G�kwd�By+ 谷歌的TPU是专用芯片。现在大部分还是通用芯片,比如GPU、CPU或者FPGA。大家经常会问,GPU和FPGA相比哪个好?像英特尔、微软等公司,在自己没有GPU的情况下,也努力推FPGA的方案。我认为,GPU和FPGA两者各有好处。简单讲,GPU比较适合在云端,从计算的有效性角度看FPGA更有优势,但真正做FPGA编程的人比GPU编程的要少很多,所以从应用、做程序的难度看,做FPGA比做GPU更加困难。 �b�wrM%B�L CPU、GPU、FPGA这些不同的通用芯片,各有各的优势,因此未来的计算很有可能向“异构计算”发展,也就是在一个平台上使用不同的芯片。我们最近的一项工作,就是研究如何更好地把AI应用到异构平台上,并使其效率更高。 -!o*�A>�N 此外,从通用走向专用也是一种趋势,因为在功耗和速度上GPU、FPGA相比专有芯片有很大差距。专用芯片是为特定场景来定制的,所以它有低功耗、低成本和高性能的优势。当然,我认为在通用和专用之间还应该有一个平衡。 e}�f#dR+(� 英伟达和AMD GPU路线图:3D堆叠内存,克服存储墙难关 s2Z��'_r�T WC�&�V9�Yk AI时代的硬件创新非常激动人心,这是一个战国群雄争霸的时代,没有一个完全通用的芯片,也没有一家公司可以统治整个市场。 5�;WE�S�k� 上面这张图展示了目前在AI时代硬件的各种解决方案。取决于应用场景,数据类型,还有资源的限制,每种硬件方案有自己各自的优势,还没有哪种方案可以一统天下。比如说谷歌的TPU,第一代做推理(inference),第二代做推理(inference)和训练(training)都是在云端做。而FPGA 或者是一些专用芯片,则可能更适合在功耗受限的端来做。 �G�kwd�By+ 谷歌的TPU是专用芯片。现在大部分还是通用芯片,比如GPU、CPU或者FPGA。大家经常会问,GPU和FPGA相比哪个好?像英特尔、微软等公司,在自己没有GPU的情况下,也努力推FPGA的方案。我认为,GPU和FPGA两者各有好处。简单讲,GPU比较适合在云端,从计算的有效性角度看FPGA更有优势,但真正做FPGA编程的人比GPU编程的要少很多,所以从应用、做程序的难度看,做FPGA比做GPU更加困难。 �b�wrM%B�L CPU、GPU、FPGA这些不同的通用芯片,各有各的优势,因此未来的计算很有可能向“异构计算”发展,也就是在一个平台上使用不同的芯片。我们最近的一项工作,就是研究如何更好地把AI应用到异构平台上,并使其效率更高。 -!o*�A>�N 此外,从通用走向专用也是一种趋势,因为在功耗和速度上GPU、FPGA相比专有芯片有很大差距。专用芯片是为特定场景来定制的,所以它有低功耗、低成本和高性能的优势。当然,我认为在通用和专用之间还应该有一个平衡。 e}�f#dR+(� 英伟达和AMD GPU路线图:3D堆叠内存,克服存储墙难关 s2Z��'_r�T  olm0O ��(9 但是,做AI硬件创新有一个很重要的挑战,就是存储墙。我举个例子,我的学生徐聪博士在惠普实验室两年前做了一个简单研究,发现随着算法的发展和数据的变大,对存储带宽的要求越来越高。同时,不管你是TPU,BPU,还是XPU,你的PU做得再快,数据还是在存储那里,你要把数据从内存搬到你的PU里。数据搬移需要的能量在整个计算中占非常大的比重,而且数据搬运的效率不会因为摩尔定律的发展而提高。 1��zNh&
" 我们再以谷歌的TPU为例,谷歌在今年6月份发布了TPU的具体技术细节,其中有一点很多人可能没有注意到,看实验数据可以发现,因为TPU所带的DDR3存储架构,带宽只有30个GB/s,虽然第一代TPU做的非常快,但由于存储带宽的限制,很多时间它是在等数据,大大限制了性能的发挥。 Q��y4eDv5 如何解决存储墙的问题?有不同的方法,其中一种方法是采用3D堆叠,我们称之为Memory Rich Processor,就是在处理器周围堆叠更多的存储器件。回过头来看,寒武纪第一代叫DianNao,第二代叫DaDianNao,DaDianNao就是为了解决存储墙问题,在处理器旁边利用eDRAM技术放了更多的内存。 �A�9� �*P7 olm0O ��(9 但是,做AI硬件创新有一个很重要的挑战,就是存储墙。我举个例子,我的学生徐聪博士在惠普实验室两年前做了一个简单研究,发现随着算法的发展和数据的变大,对存储带宽的要求越来越高。同时,不管你是TPU,BPU,还是XPU,你的PU做得再快,数据还是在存储那里,你要把数据从内存搬到你的PU里。数据搬移需要的能量在整个计算中占非常大的比重,而且数据搬运的效率不会因为摩尔定律的发展而提高。 1��zNh&
" 我们再以谷歌的TPU为例,谷歌在今年6月份发布了TPU的具体技术细节,其中有一点很多人可能没有注意到,看实验数据可以发现,因为TPU所带的DDR3存储架构,带宽只有30个GB/s,虽然第一代TPU做的非常快,但由于存储带宽的限制,很多时间它是在等数据,大大限制了性能的发挥。 Q��y4eDv5 如何解决存储墙的问题?有不同的方法,其中一种方法是采用3D堆叠,我们称之为Memory Rich Processor,就是在处理器周围堆叠更多的存储器件。回过头来看,寒武纪第一代叫DianNao,第二代叫DaDianNao,DaDianNao就是为了解决存储墙问题,在处理器旁边利用eDRAM技术放了更多的内存。 �A�9� �*P7  �
}?eO.l�{ �
}?eO.l�{  xG_LEk( zD xG_LEk( zD  nX�U`^<�nA 2002-2003年,我在IBM工作期间开始接触3D堆叠芯片技术,在2003年加入学术界后,一直致力于研究如何把这项技术用于新架构的设计上。在2012-2013年期间,我们与AMD研究部门合作,探索如何把3D堆叠的内存放在GPU旁边,帮助解决存储墙的问题[2]。 W;�Y�"J�_� 2015年6月,AMD推出了世界上第一款使用3D堆叠的GPU,在Fury X GPU内部集成了4GB的3D堆叠的HBM(High-bandwidth Memory),大大减少数据搬移的消耗。这个3D堆叠的技术推出后到现在,两年多的时间里,被很多厂商合作使用。 �V^* ];`�^ 在处理器内部集成的存储也越来越多,比如2015年AMD集成了4GB的HBM,今年发布的AMD和NVIDIA的Vega和Volta GPU都集成了16GB的HBM2。而其他公司的一些最新的AI芯片架构,也都集成了3D堆叠存储,比如Intel Nervana也用3D HBM,而Wave Computing用的是美光(Micron)的HMC,另外一种形式的3D堆叠存储。 U/}("i![Dy nX�U`^<�nA 2002-2003年,我在IBM工作期间开始接触3D堆叠芯片技术,在2003年加入学术界后,一直致力于研究如何把这项技术用于新架构的设计上。在2012-2013年期间,我们与AMD研究部门合作,探索如何把3D堆叠的内存放在GPU旁边,帮助解决存储墙的问题[2]。 W;�Y�"J�_� 2015年6月,AMD推出了世界上第一款使用3D堆叠的GPU,在Fury X GPU内部集成了4GB的3D堆叠的HBM(High-bandwidth Memory),大大减少数据搬移的消耗。这个3D堆叠的技术推出后到现在,两年多的时间里,被很多厂商合作使用。 �V^* ];`�^ 在处理器内部集成的存储也越来越多,比如2015年AMD集成了4GB的HBM,今年发布的AMD和NVIDIA的Vega和Volta GPU都集成了16GB的HBM2。而其他公司的一些最新的AI芯片架构,也都集成了3D堆叠存储,比如Intel Nervana也用3D HBM,而Wave Computing用的是美光(Micron)的HMC,另外一种形式的3D堆叠存储。 U/}("i ��7)RDu,fx 谷歌第一代TPU数据发布后,当时我的第一反应就是谷歌的下一代TPU一定会放3D堆叠的内存。虽然现在还没有第二代TPU的具体技术细节,但是根据今年8月Jeff Dean在Hotchips上透露的信息,现在看谷歌第二代TPU放上了多少内存?不是4G、不是8G、不是16G,而是64G,谷歌第二代TPU放上了64G的内存,带宽从第一代的30 GB/s到现在的600 GB/s。 =EJ8J;y�_f 最近还有一个有意思的消息,两个月前,AMD负责GPU的高级副总裁Raja Koduri来我们学校UCSB休假了40天,就在不久前他宣布加盟Intel。同时,AMD和英特尔也宣布了一个新产品,联手干了一件事情,把Intel的CPU和AMD的GPU集成放在一起,同时为了解决存储墙问题,再放一个堆叠的3D内存。有人开玩笑说,因为AI时代的到来,“AI”引发了A(AMD)和I(Intel)的联手合作。
Vs�1�H)T% 在学术界做更有前瞻性的研究:针对AI应用计算存储一体化,未来5年从底层到高层打通 dDu8n+(8 L 所有的这些现象都让我们看到了最近在AI应用驱动下计算硬件架构上的创新,包括英伟达、英特尔、谷歌,AMD这些大公司,还有寒武纪、深鉴科技、地平线这样的初创公司,甚至包括比特大陆都转型在做AI芯片的设计。那么在学校做科研的还能做什么?学校没有像谷歌英伟达这样有几千人的团队,也没有那么多资源,我们做的事情是要往前看,利用学校创新能力的优势,做更有前瞻性的研究,看到现在公司还没有办法做或者还没有精力去做的研究方向。 nYsB�^Nr6� 我们现在考虑的也是针对存储进行优化,研究计算存储的一体化的架构。传统意义上的冯·诺依曼架构,计算单元不管有多快,数据一定是从硬盘搬到主存,再搬到计算单元(PU)里面。我刚刚提到的3D堆叠是一种方法,可以把更多的内存放在计算处理单元里,以减少芯片内外的数据搬移,提高计算和存储之间的带宽。不过,想想我们的人脑,人类的大脑是有没有计算和存储的区别,有没有说比如用左半球来计算,右半球做存储吗?没有,我们人脑本身的计算和存储都发生在同一个地方,不需要数据搬移。 6o�:b(v&Oo 所以,未来的计算机体系结构可能要改变传统的把计算和存储分开的冯·诺依曼架构。其中的一个创新架构的研究方向是计算和存储一体化(process-in-memory),在存储里面加上计算的功能。例如,我们的研究团队在去年的计算机架构顶级会议ISCA就发表了一个工作叫PRIME架构[3],在新型存储器件ReRAM里面做计算的功能,让存储器件做神经网络的计算。今年,我们和新竹清华大学张孟凡教授团队以及北京清华大学刘勇攀教授团队和汪玉教授团队合作,把PRIME的架构在150nm工艺下流片, 在阻变存储阵列里实现了计算存储一体化的神经网络。我们发现,当计算和存储都放在一起,在内存里面实现神经网络计算的时候,功耗可以降低20倍,速度提高50倍。所以,省去数据搬移,计算的功耗和性能都可以大大提高。 v[Mh�[CyB� ��7)RDu,fx 谷歌第一代TPU数据发布后,当时我的第一反应就是谷歌的下一代TPU一定会放3D堆叠的内存。虽然现在还没有第二代TPU的具体技术细节,但是根据今年8月Jeff Dean在Hotchips上透露的信息,现在看谷歌第二代TPU放上了多少内存?不是4G、不是8G、不是16G,而是64G,谷歌第二代TPU放上了64G的内存,带宽从第一代的30 GB/s到现在的600 GB/s。 =EJ8J;y�_f 最近还有一个有意思的消息,两个月前,AMD负责GPU的高级副总裁Raja Koduri来我们学校UCSB休假了40天,就在不久前他宣布加盟Intel。同时,AMD和英特尔也宣布了一个新产品,联手干了一件事情,把Intel的CPU和AMD的GPU集成放在一起,同时为了解决存储墙问题,再放一个堆叠的3D内存。有人开玩笑说,因为AI时代的到来,“AI”引发了A(AMD)和I(Intel)的联手合作。
Vs�1�H)T% 在学术界做更有前瞻性的研究:针对AI应用计算存储一体化,未来5年从底层到高层打通 dDu8n+(8 L 所有的这些现象都让我们看到了最近在AI应用驱动下计算硬件架构上的创新,包括英伟达、英特尔、谷歌,AMD这些大公司,还有寒武纪、深鉴科技、地平线这样的初创公司,甚至包括比特大陆都转型在做AI芯片的设计。那么在学校做科研的还能做什么?学校没有像谷歌英伟达这样有几千人的团队,也没有那么多资源,我们做的事情是要往前看,利用学校创新能力的优势,做更有前瞻性的研究,看到现在公司还没有办法做或者还没有精力去做的研究方向。 nYsB�^Nr6� 我们现在考虑的也是针对存储进行优化,研究计算存储的一体化的架构。传统意义上的冯·诺依曼架构,计算单元不管有多快,数据一定是从硬盘搬到主存,再搬到计算单元(PU)里面。我刚刚提到的3D堆叠是一种方法,可以把更多的内存放在计算处理单元里,以减少芯片内外的数据搬移,提高计算和存储之间的带宽。不过,想想我们的人脑,人类的大脑是有没有计算和存储的区别,有没有说比如用左半球来计算,右半球做存储吗?没有,我们人脑本身的计算和存储都发生在同一个地方,不需要数据搬移。 6o�:b(v&Oo 所以,未来的计算机体系结构可能要改变传统的把计算和存储分开的冯·诺依曼架构。其中的一个创新架构的研究方向是计算和存储一体化(process-in-memory),在存储里面加上计算的功能。例如,我们的研究团队在去年的计算机架构顶级会议ISCA就发表了一个工作叫PRIME架构[3],在新型存储器件ReRAM里面做计算的功能,让存储器件做神经网络的计算。今年,我们和新竹清华大学张孟凡教授团队以及北京清华大学刘勇攀教授团队和汪玉教授团队合作,把PRIME的架构在150nm工艺下流片, 在阻变存储阵列里实现了计算存储一体化的神经网络。我们发现,当计算和存储都放在一起,在内存里面实现神经网络计算的时候,功耗可以降低20倍,速度提高50倍。所以,省去数据搬移,计算的功耗和性能都可以大大提高。 v[Mh�[CyB� 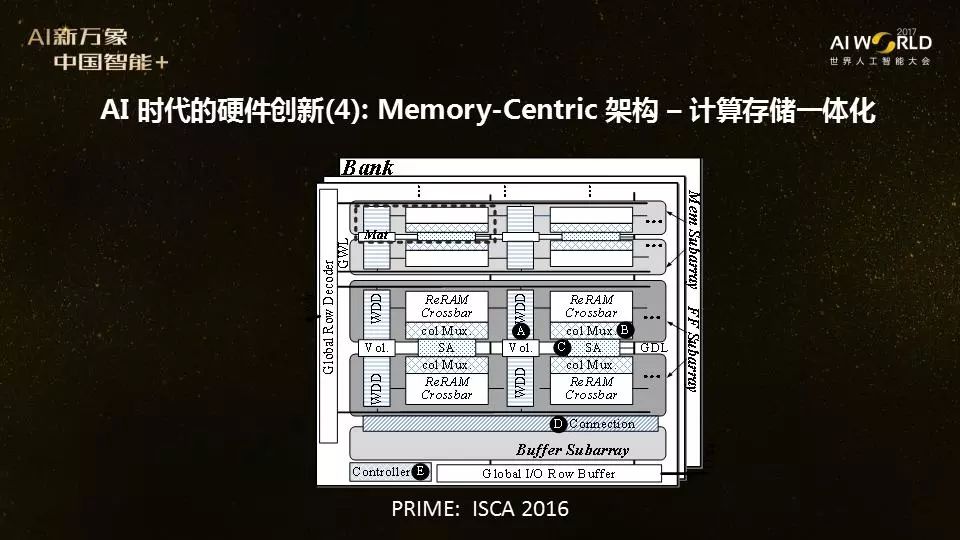 �3<X�P/c"; �3<X�P/c";  tDC��?St1� 巧合的是,我们在架构会议ISCA 2016和芯片设计会议VLSI Symposium 2017发表了PRIME架构的想法之后,今年10月,IBM在《自然》也发了一篇文章,宣布在相变存储器上实现了同样的针对AI应用的“In memory computing”这个概念。IBM做的也是在存储里面实现神经网络计算的功能,区别在于我们用的是阻变存储器(ReRAM),而IBM用的是相变存储器(PCRAM),共同点都是基于利用这些新型存储器件的模拟计算功能来实现神经网络的计算。 t�6�q7�w�� tDC��?St1� 巧合的是,我们在架构会议ISCA 2016和芯片设计会议VLSI Symposium 2017发表了PRIME架构的想法之后,今年10月,IBM在《自然》也发了一篇文章,宣布在相变存储器上实现了同样的针对AI应用的“In memory computing”这个概念。IBM做的也是在存储里面实现神经网络计算的功能,区别在于我们用的是阻变存储器(ReRAM),而IBM用的是相变存储器(PCRAM),共同点都是基于利用这些新型存储器件的模拟计算功能来实现神经网络的计算。 t�6�q7�w��  �F ���,;B 那么,在现有成熟的DRAM存储器件上,能不能做类似的事情呢?也是可能的。我们最近和三星存储研究部门一起合作的一个工作,刚刚在10月份的第50届MICRO会议上发表,这个DRISA架构就是在DRAM的工艺上,实现了卷积神经网络的计算功能[4]。 �iv!;�gMco 最近,美国的SRC启动了一个1.5亿美金的5年研究计划JUMP [5],设置了6个不同的研究中心,这6个不同的研究中心代表了6个不同的未来研究方向。其中一个方向叫Intelligent memory and storage,这个研究中心由弗吉尼亚大学的一位教授和我一起共同领导,包含了东西海岸两个团队共20多位教授(包括多名美国工程院院士和IEEE/ACM Fellow),带领几十名博士生和博士后,包含了从底层的存储器件设计,到电路和架构设计,再到系统和软件各个方向的专业人士。我们这个团队的目标是研究计算存储一体化,在未来五年希望能够从底层到高层打通。 7|@FN7]5NF 在我们这个研究中心未来的蓝图里,不仅仅是在计算架构层面要做革新,往下包括像针对不同存储介质的电路都要做相应的改变,往上的ecosystem也很重要,所以我们的团队不仅仅包含硬件研究人员,还需要在编程语言,编译器,操作系统和应用软件都需要有相应的创新。同时,在人工智能领域,我们认为所谓的domain knowledge也非常重要,我们选了几个AI应用领域方向,包括视频分析,精准医疗和认知计算,都邀请相应的专家一起来合作。我们把AI的ABC(算法+大数据+计算),又加上D(Domain knowledge)和E(Ecosystem),探究计算存储一体化,希望能够使下一代AI芯片能够有更进一步的发展。 �dz6�&TdEl �F ���,;B 那么,在现有成熟的DRAM存储器件上,能不能做类似的事情呢?也是可能的。我们最近和三星存储研究部门一起合作的一个工作,刚刚在10月份的第50届MICRO会议上发表,这个DRISA架构就是在DRAM的工艺上,实现了卷积神经网络的计算功能[4]。 �iv!;�gMco 最近,美国的SRC启动了一个1.5亿美金的5年研究计划JUMP [5],设置了6个不同的研究中心,这6个不同的研究中心代表了6个不同的未来研究方向。其中一个方向叫Intelligent memory and storage,这个研究中心由弗吉尼亚大学的一位教授和我一起共同领导,包含了东西海岸两个团队共20多位教授(包括多名美国工程院院士和IEEE/ACM Fellow),带领几十名博士生和博士后,包含了从底层的存储器件设计,到电路和架构设计,再到系统和软件各个方向的专业人士。我们这个团队的目标是研究计算存储一体化,在未来五年希望能够从底层到高层打通。 7|@FN7]5NF 在我们这个研究中心未来的蓝图里,不仅仅是在计算架构层面要做革新,往下包括像针对不同存储介质的电路都要做相应的改变,往上的ecosystem也很重要,所以我们的团队不仅仅包含硬件研究人员,还需要在编程语言,编译器,操作系统和应用软件都需要有相应的创新。同时,在人工智能领域,我们认为所谓的domain knowledge也非常重要,我们选了几个AI应用领域方向,包括视频分析,精准医疗和认知计算,都邀请相应的专家一起来合作。我们把AI的ABC(算法+大数据+计算),又加上D(Domain knowledge)和E(Ecosystem),探究计算存储一体化,希望能够使下一代AI芯片能够有更进一步的发展。 �dz6�&TdEl
|











