TA的每日心情 | 怒
前天 10:56 |
|---|
签到天数: 85 天 [LV.6]常住居民II
三级逆天
- 积分
- 53741
     
|
马上注册,结交更多好友,享用更多功能,让你轻松玩转社区
您需要 登录 才可以下载或查看,没有账号?立即注册
×
AMD 的 3D V-Cache 标志着该公司首次涉足 3D 封装,该公司在 Hot Chips 33 上的演示中分享了其制造工艺背后的更多细节。
3D V-Cache 使用了一种新颖的混合键合技术,融合了额外的 64MB 7nm SRAM 缓存垂直堆叠在 Ryzen 计算小芯片的顶部,使每个 Ryzen 芯片的 L3 缓存数量增加三倍。
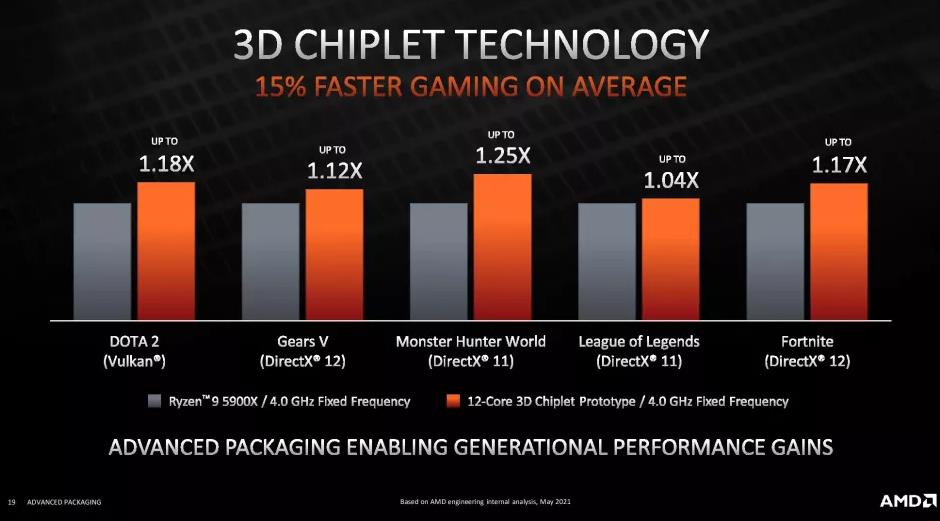
这项新技术可以为每个芯片提供高达 192MB 的 L3 缓存,并且 AMD 演示了 Ryzen 9 5900X 使用新缓存在 1080p 游戏中获得了 15% 的性能提升,这大致是我们可以从新的缓存中获得的性能。
CPU 微架构和/或进程节点。但是,AMD 使用与标准 Ryzen 5000 型号相同的 7nm 节点和 Zen 3 架构完成了这一壮举。这一进步还伴随着芯片顶部堆叠的单个裸片——AMD 表示未来它可以堆叠不止一层,这将进一步提高容量。
AMD 在展示后透露,它可以通过新的 3D V-Cache 芯片实现与标准 Ryzen 型号类似的产量,这意味着它已经跨越了带来芯片所需的障碍,这些芯片将于今年年底投入生产,到市场。
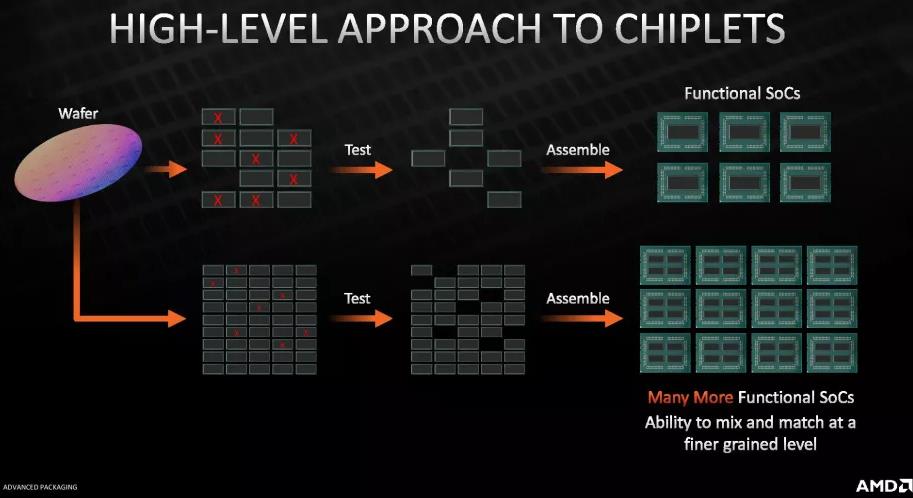
AMD 使用台积电的 SoIC 工艺将计算芯片顶部的 SRAM 小芯片与连接两个芯片的 TSV 的直接铜对铜电介质接合融合在一起。这种技术不使用焊料微凸点来连接两个芯片,从而实现了更密集、更高效的互连,其互连密度是 2D 小芯片的 200 倍。
台积电采用两相键合技术将两个芯片熔合在一起。第一阶段在室温下使用亲水性电介质到电介质键合工艺,然后对电介质连接进行退火键合。第二阶段是通过固态扩散形成键的直接铜对铜键合。AMD 表示,该技术使用类似硅晶圆厂的制造技术,后端类似于 TSV,这意味着生产流程类似于常规芯片的生产流程。
AMD 将 SRAM 芯片保持在底层 L3 缓存的中央,以减少 SRAM 暴露于 CPU 内核的热量。此外,AMD 使用相同的混合键合工艺在 CPU 内核上放置结构硅,从而为小芯片创建统一的高度,有助于冷却芯片。
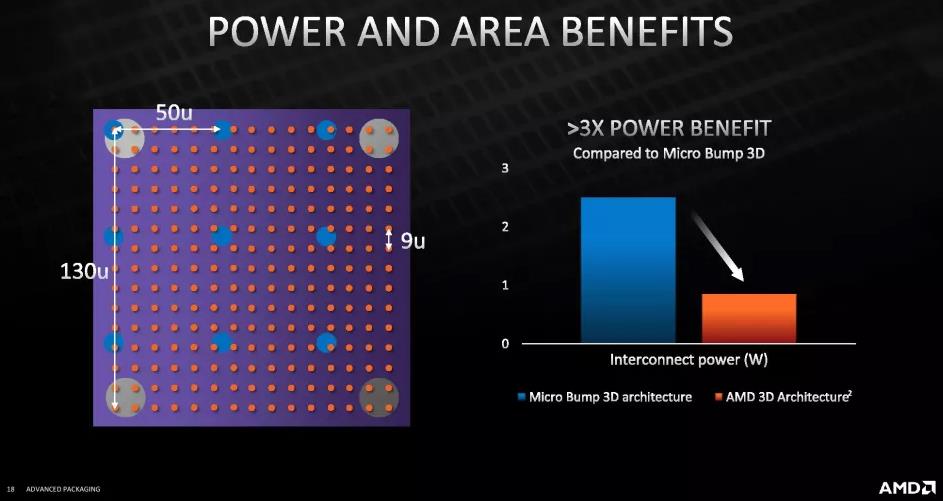
相对于微凸点 3D 连接,AMD 表示 3D V-Cache 的互连效率是互连效率的三倍,每比特能耗不到三分之一,互连密度提高 15 倍,以及更好的信号和功率传输特性。
AMD 的方法在两个芯片之间提供 2 TB/s 的吞吐量。该公司表示,延迟影响很小,并且在更高容量的 L3 缓存的标准范围内(缓存的原始访问时间随容量扩展)。
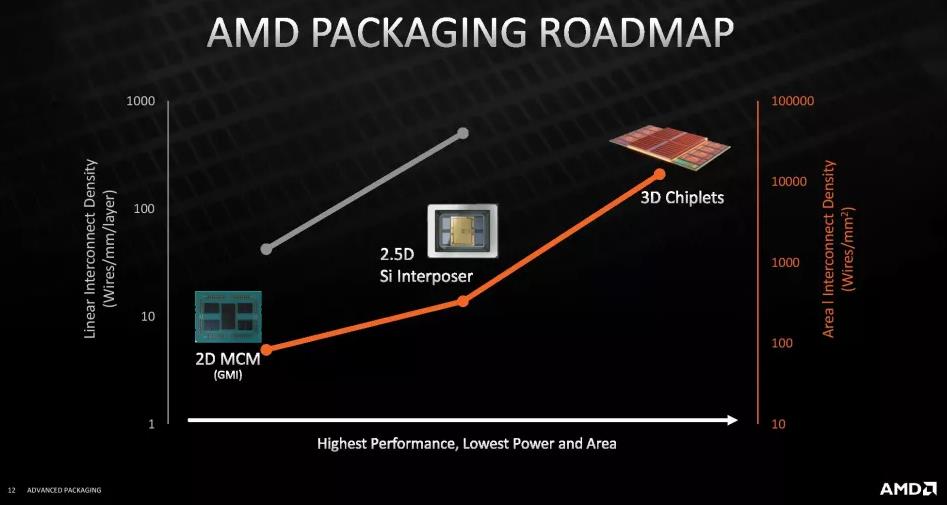
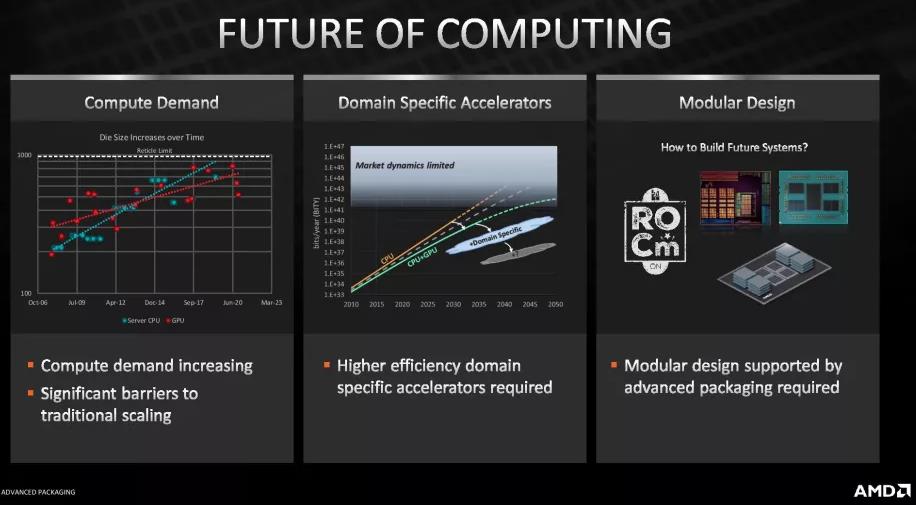
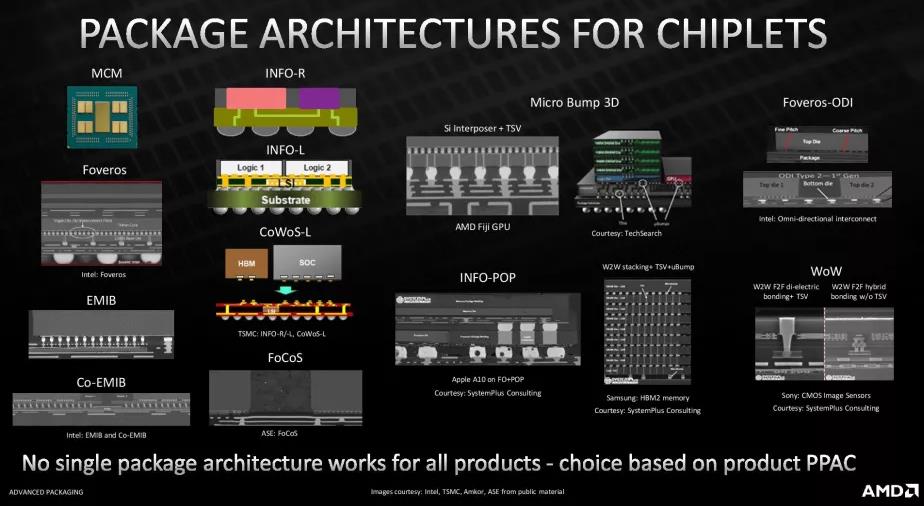
第一张图显示了三种不同互连方法之间的互连密度。虽然 AMD 的新互连具有 9 微米 (μm) 的间距(TSV 之间的距离),但标准 C4 封装的间距为 130 微米,而 Microbump 3D 的间距为 50 微米。
相比之下,英特尔出货的第一代 EMIB 连接的间距为 55 微米,而其将于 2023 年推出的第二代 EMIB 的间距为 45 微米。然而,英特尔即将推出的 Foveros Direct 是最直接可比的互连技术,英特尔声称它在 2023 年底上市时的间距将低于 10 μm。同时,台积电的 9 μm 混合键合将在明年早些时候上市AMD 的 3D V-Cache 处理器。
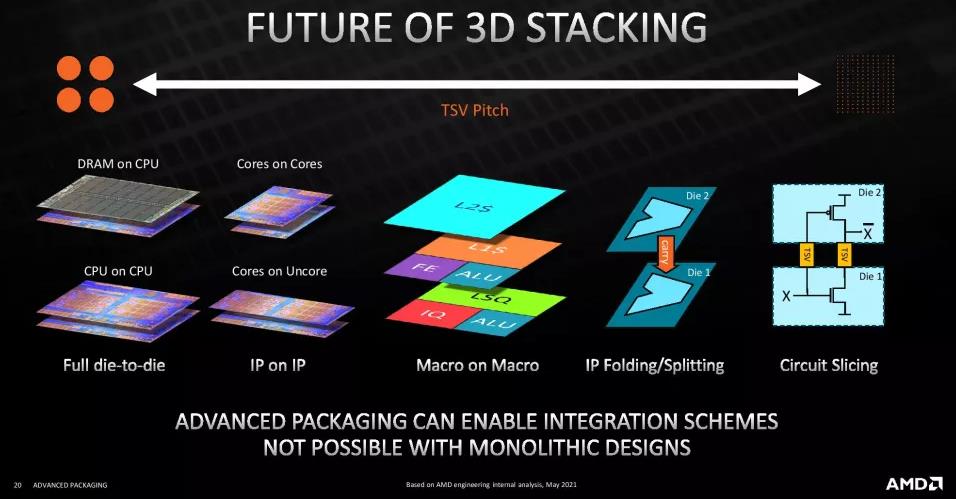
AMD 当前的内存逻辑只是该行业更广泛趋势的开始。随着 TSV 间距在连续几代技术中改进,它将解锁其他更精细的堆叠技术,例如 CPU 上的 DRAM/HBM,以及将整个 CPU 堆叠在 CPU 之上。
进一步的发展可以找到更精细的方法,例如将 CPU 核心堆叠在其他核心之上,并将核心堆叠在非核心之上(英特尔已经在 Lakefield 中做到了这一点)。更进一步,我们可以看到宏对宏的堆叠,这意味着核心微架构的各种元素相互堆叠,甚至 IP 折叠/拆分和电路切片。
自然,这些遥远的技术还没有出现在绘图板上,将带来很多挑战,特别是在散热方面,但 AMD 和其他公司确实看到这些技术在未来出现。
|
|

 再发某公司的PADS格式 PCB封装库全套共享
再发某公司的PADS格式 PCB封装库全套共享 Allegro超强最全模仿PADS快捷键实现Z切换层
Allegro超强最全模仿PADS快捷键实现Z切换层 英伟达GPU模组-middleplane模组-18层板
英伟达GPU模组-middleplane模组-18层板 基于STM32智能鱼缸控制系统
基于STM32智能鱼缸控制系统 RK3576图片展示
RK3576图片展示 xilinx XC7Z010/020-TLZ7x-EasyEVM-A3
xilinx XC7Z010/020-TLZ7x-EasyEVM-A3 TL138_1808_6748F-EVM-A2_16D2
TL138_1808_6748F-EVM-A2_16D2 allegro羊皮卷
allegro羊皮卷 抗噪液晶屏驱动/抗干扰液晶驱动芯片/LCD显
抗噪液晶屏驱动/抗干扰液晶驱动芯片/LCD显 矢量网络分析仪的技术原理和应用场景
矢量网络分析仪的技术原理和应用场景 射频微电子学 原书第2版 精编版,(美)毕查
射频微电子学 原书第2版 精编版,(美)毕查 PCB电阻修改封装
PCB电阻修改封装 再发某公司的PADS格式封装大全 PCB封装库全
再发某公司的PADS格式封装大全 PCB封装库全 60N10 N型沟道MOSFET产品概述
60N10 N型沟道MOSFET产品概述

 发表于 2021-8-26 08:56:39
发表于 2021-8-26 08:56:39


















")
")