|
|
马上注册,结交更多好友,享用更多功能,让你轻松玩转社区
您需要 登录 才可以下载或查看,没有账号?立即注册
×
对话式人工智能(AI)正受到广泛关注。在网站上向AI提问时,它会像真人写的一样用自然的语句做出回答。由于美国谷歌和微软等大型科技企业参与相关竞争,这更吸引着全球热切的目光。
但是,直至目前公开的对话AI仍存在严重缺陷。虽然是由AI读取大量数据,可以给出像模像样的答案,但也存在很多致命性错误。很难说AI真正理解了问题和自己用于作答的词汇的“含义”。
通过梳理“ChatGPT”等对话AI出现的诸多错误,就可以发现机器要达到真正的智能所面临的核心技术课题。
“老师”和“亲妈”将展开竞争
由于2022年秋季美国初创企业OpenAI免费公开的ChatGPT在全世界引发热议,此前一直不打算向公众公开对话AI的谷歌改变了方针。
2月6日,谷歌首席执行官(CEO)桑德尔·皮查伊亲自在官方博客上宣布,未来几周内将在搜索服务中嵌入名为“Bard”的对话AI并投入使用。
谷歌CEO桑德尔·皮查伊宣称AI是谷歌最重要的技术领域(2022年10月,东京都涩谷区)
据称,在搜索栏中输入提问内容后,会显示用自然流畅的语句给出的答案,以及回答问题时作为依据所参考的网页链接。
事实上,领先一步的ChatGPT的基础是基于AI的大型语言模型,该模型建立在谷歌开发的被称为“Transformer”的技术之上。不仅如此,谷歌还拥有数据量和能够生成的句子类型数量远多于OpenAI的模型。对于OpenAI来说,谷歌公开对话AI,就好比“老师”突然变成了竞争对手。
在“老师”发布消息之后,“亲妈”也跟着行动起来。在谷歌宣布公开对话AI的第二天(2月7日),OpenAI的大股东微软也发布消息称,在搜索服务必应(Bing)中嵌入了基于OpenAI技术的对话功能。据称,通过与搜索功能同时使用,可以根据最新信息以自然流畅的语句做出回答,还能够对长达好几页的文档进行概括提炼。
不善于追逐最新信息
谷歌和微软都强调,通过同时使用搜索和生成自然语言的功能,可以根据网上的最新信息生成语句。反过来说,对话AI此前一直不擅长追逐最新信息。
ChatGPT等的大型语言模型,每次更新信息内容时,都需要重新读取数量庞大的文献数据。因为很难频繁更新,所以模型内保存的信息大多比较旧。
比如,当询问ChatGPT“洛杉矶湖人队(Los Angeles Lakers)最近一场比赛的上场阵容”时,得到的回答是“我只具备2021年之前的知识,无法回答您的问题”。
谷歌和微软的对话AI同时使用网络搜索,因此会在信息的同步性和准确性方面取得巨大进步。尽管如此,谷歌在2月8日进行Bard的演示时,仍显示出了错误信息,说是美国航空航天局(NASA)的詹姆斯韦伯太空望远镜成功拍摄到了史上第一张太阳系外行星的照片。这一错误信息随后引发争议。可见,信息的准确性仍有不少课题需要解决。
缺乏常识和逻辑
除了上述的问题外,对话AI还存在根本性的课题。目前推出的对话AI基本上都很难说已经可以理解自己所使用的词汇的概念、含义、事物或现象的因果关系等“逻辑”。正因为如此,才会反复出现简单的事实误认。
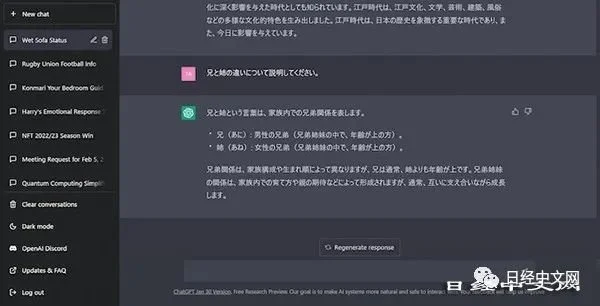
例如,向ChatGPT询问“哥哥和姐姐有什么不同”时,得到的回答是“虽然兄弟姐妹关系因家庭结构和出生顺序不同而存在差异,但哥哥通常比姐姐年龄大”。之所以给出这样不知所以然的答案,是因为没有“理解”哥哥、姐姐等词语的概念、相互之间的关系、家庭构成等全局情况。
向ChatGPT询问“哥哥”和“姐姐”的区别时,得到的回答含有错误内容
之所以会出现这样的错误,是因为现在使用的绝大部分语言模型是机器学习型AI。因此,使用的语言基本上是单词和短语的“排列”,机器通过读入数量庞大的过去的文献来识别排列类型。然后再计算出各类型出现的概率,寻找出接在问题之后的概率较高的字符串并加以显示。
例如,在日语语言模型中输入“我が輩(中文译:我)”,使其生成后续的语句时,答案就会显示在书籍、新闻报道、网站留言中出现概率最高的排列组合类型,即“は猫である(中文译:是猫)”(见下图)。ChatGPT还可以直接生成与“夏目漱石风格”的小说相类似的句子。
(编者注:《我が輩は猫である》是日本作家夏目漱石的长篇代表作,中文译名为《我是猫》)
语言模型是“学习”在基本单词之后衔接什么单词的概率,并生成句子。(资料由NTT数据尖端技术提供)
简单计算也会出错
也就是说,聊天AI不过是根据读取数据找出概率高的词序,并不是理解单词、语句的“含义”以及家庭成员之间的关系等“常识”。因此,它不擅长回答那些不理解意义和常识就难以回答的问题。
由于不擅长逻辑,因此Chat GPT也不擅长简单的计算。让它做任意4位数之间的乘法,大都会算错,并且反复输入相同算式时,总是给出错误的答案。
让ChatGPT计算4567×5678的乘法,会给出错误的答案。大规模语言模型不擅长世上文献很少的小学生水平的数学。
也就是说,现有的聊天AI不适合用于调查事实。而应该仅限于在不管内容的真实性和准确性,只需要自动生成自然语句和软件程序等文字列的目的时使用。
机器学习的极限和下一个AI
那么,拥有与人类相当的“智能”的AI的开发到底有没有取得进展呢?熟悉日本国内外动向的日本科学技术振兴机构研究开发战略中心的研究员福岛俊一表示:“具有逻辑思考、常识和认知的新一代AI的研究从几年前就在推进”。
AI掀起过3次新技术浪潮。分别是1960年代、1980年代及从2010年代持续至今的第三次。其中,1960年代和1980年代是计算机根据人类预先编制好的逻辑,分析数据得出结论。由此也发现编制支持现实的无数逻辑不太可能,于是上一波浪潮在1990年代开始走向衰退。
2010年代开始、持续到现在的AI浪潮并不是人类思考逻辑,而是由让计算机自己归纳出数据的各种类型的机器学习来引领。随着相当于计算机大脑的半导体性能越来越高以及互联网普及,可以收集全世界的数据,被称为“深层学习”的可以识别复杂类型的软件技术问世等要素全部得以实现。
如果将机器学习型AI和“大数据”结合起来,限定于特定用途,就可以完成人类不可能完成的工作。比如,通过读取大量的面部照片,提高图形识别能力,从而实现智能手机开机时的面容解锁。
Digital Garage董事伊藤穰一指出了依赖机器学习的AI的“极限”
不过,要实现自动驾驶及自律型多功能机器人,相当于头脑的AI要具有识别眼前物体和周围情况的能力,其中包括过去没经历过的情况。
这需要基于逻辑和常识的推论能力,仅靠依赖“过去”事例的机器学习型模型并不能顺利实现。熟悉尖端技术动向的Digital Garage公司董事伊藤穰一指出:“谷歌、特斯拉及苹果仍很难将自动驾驶汽车推向实用说明依靠机器学习的AI存在极限”。
“别说人类,就连猫狗的智能都远未达到”
对话型AI缺乏“常识”和“道理”也源于根据数据以归纳法方式探索相关类型的机器学习型AI的弱点。
兼具常识和逻辑思考的新一代AI如何才能实现?参考人类儿童自然掌握语言、空间认识及社会关系等的过程,让计算机学习逻辑和常识的研究正以脑科学家和认知科学家也参与的跨学科途径推进。另外,也有将在第2次AI浪潮下失败的人类输入逻辑和常识与尖端的深层学习相融合的尝试。
关于通过机器实现与人类接近的智能这一长期目标与现有AI技术的差距,开拓深层学习基本技术的美国Meta首席AI科学家、纽约大学教授Yann Lucan形容道:“目前先别说人类,就连猫狗的智能都远未达到”。
我们不能因为看到对话AI的流畅文章就误以为AI智能已经接近超越人类的“特异功能”(Singularity)。人类的科学技术在达到这一水平之前还需要实现众多突破。 |
|

 再发某公司的PADS格式 PCB封装库全套共享
再发某公司的PADS格式 PCB封装库全套共享 Allegro超强最全模仿PADS快捷键实现Z切换层
Allegro超强最全模仿PADS快捷键实现Z切换层 RK3576图片展示
RK3576图片展示 xilinx XC7Z010/020-TLZ7x-EasyEVM-A3
xilinx XC7Z010/020-TLZ7x-EasyEVM-A3 TL138_1808_6748F-EVM-A2_16D2
TL138_1808_6748F-EVM-A2_16D2 CH7026B-RGB转VGA
CH7026B-RGB转VGA 120W 电源板PCB文件共享
120W 电源板PCB文件共享 allegro羊皮卷
allegro羊皮卷 龙迅LT7911UXC+RTS5880 做的VR眼镜 方案原
龙迅LT7911UXC+RTS5880 做的VR眼镜 方案原 再发某公司的PADS格式封装大全 PCB封装库全
再发某公司的PADS格式封装大全 PCB封装库全 家电/温控器触摸IC高抗干扰触摸芯片VK3606D
家电/温控器触摸IC高抗干扰触摸芯片VK3606D 60N10 N型沟道MOSFET产品概述
60N10 N型沟道MOSFET产品概述 从零开始学ALTIUM DESIGNER电路设计与PCB制
从零开始学ALTIUM DESIGNER电路设计与PCB制 电子天线罩测试仪的技术原理和应用场景
电子天线罩测试仪的技术原理和应用场景



 发表于 2023-2-16 18:13:37
发表于 2023-2-16 18:13:37

























")
")