|
|
人工智慧(AI)可说是2016年运算领域最热门的话题,厂商竞相开发专用晶片的战争已经开打…
对运算产业来说,在过去的2016年应该没有一个概念比人工智慧(AI)更热门;跨入2017年,专家们表示,人工智慧生态圈的需求成长会更加迅猛。主要集中在为深度神经网路找寻性能和效率更适合的“推理(inference)引擎”。
现在的深度学习系统仰赖软体定义网路和巨量资料学习产生的超大型运算能力,并靠此来实现目标;遗憾的是,这类型的运算配置是很难嵌入到那些运算能力、记忆体容量大小和频宽都有限制的系统中(例如汽车、无人机和物联网设备)。
这为业界带来了一个新的挑战──如何透过创新将深度神经网路运算能力嵌入到终端设备中。如(已经被Intel收购的)电脑视觉处理器设计业者Movidius执行长Remi El-Ouazzane在几个月前就说过,将人工智慧布署在网路边缘将会是一个大趋势。
在问到为什么人工智慧会被“赶”到网路边缘的时候,法国原子能委员会(CEA)架构、IC设计与嵌入式软体(Architecture, IC Design and Embedded Software)部门院士Marc Duranton提出三个原因:安全性(safety)、隐私(privacy)和经济(economy);他认为这三点是驱动业界在终端处理资料的重要因素,而未来将会衍生更多“尽早将资料转化为资讯”的需求。
Duranton指出,试想自动驾驶车辆,如果其目标是安全性,那些自动驾驶功能就不应该只仰赖永不中断的网路连线;还有例如老人在家里跌倒了,这种情况应该由本地监测装置在当场就判断出来,考虑到隐私因素,这是非常重要的。而他补充指出,不必收集家里10台摄影机的所有影像并传输以触发警报,这也能降低功耗、成本与资料容量。
AI竞赛正式展开
从各方面看来,晶片供应商已经意识到推理引擎的成长需求;包括Movidus (Myriad 2), Mobileye (EyeQ 4 & 5) 和Nvidia (Drive PX)在内的众多半导体公司正竞相开发低功耗、高性能的硬体加速器,好让机器学习功能在嵌入式系统中被更妥善执行。
从这些厂商的动作和SoC的发展方向看来,在后智慧型手机时代,推理引擎已经逐渐成为半导体厂商追逐的下一个目标市场。
在今年稍早,Google推出了张量处理单元(TPU),可说是产业界积极推动机器学习晶片创新的一个转捩点;Google在发表晶片时表示,TPU每瓦性能较之传统的FPGA和GPU将会高一个等级,此外并指出这个加速器还被已被应用于今年年初风靡全球的AlphaGo系统。但是迄今Google并未披露TPU的规格细节,也不打算让该元件在商业市场上销售。
很多SoC从业者从Google的TPU中得出了一个结论──机器学习需要客制化的架构;但在他们针对机器学习进行晶片设计的时候,他们又会对晶片的架构感到疑惑,同时想知道业界是否已经有了一种评估不同形态下深度神经网路(DNN)性能的工具。
性能评估工具即将问世
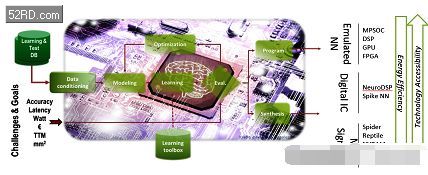
CEA表示,该机构已经准备好为推理引擎探索不同的硬体架构,他们已经开发出一种名为N2D2的软体架构,能够帮助设计工程师探索和生成DNN架构;Duranton指出:“我们开发这个工具之目的,是为DNN选择适合的硬体目标。”CEA将会在2017年第一季释出N2D2的开放源码。
N2D2的特色在于不仅是以识别精确度为基础来比较硬体,它还能从处理时间、硬体成本和功耗等多个方面执行比较;Duranton表示,因为针对不同应用的深度学习,需求之硬体设定参数也会有所不同,因此以上几个比较非常重要。N2D2能为现有CPU、GPU和FPGA等硬体(包括多核心与众多核心)提供一个性能参考标准。
N2D2运作原理
边缘运算的障碍
CEA已经针对如何把DNN完美地推展到边缘运算(edge computing)进行了深入研究;Duranton指出,其中最大的障碍在于因为功耗、记忆体容量尺寸和延迟等限制,“浮点”式伺服器方案不适用;而其他障碍还包括:“需要大量的MAC、频宽和晶片上记忆体容量。”
所以说,采用整数(Integer)而非浮点运算是最需要优先考量的问题…还有别的吗?Duranton认为,这种专属架构也需要采用新的编码方式,例如“棘波编码(spike coding)”;CEA的研究人员研究了神经网路的特性,发现这种网路能容忍运算误差,使其适用于“近似运算(approximate computation)”。
如此一来,甚至于不需要采用二进位编码;而Duranton解释,其好处在于诸如棘波编码的时间编码(temporal coding),能在边缘运算提供更具能源效益的结果。棘波编码之所以具吸引力,是因为棘波编码──或是以事件为基础(event-based)的──系统能展现实际神经系统内的资料如何被解码。
此外,以事件为基础的编码能相容专用的感测器和预处理(pre-processing)。这种和神经系统极度相似的编码方式,使得类比和数位混合讯号更容易实现,也能够帮助研究者打造低功耗的小型硬体加速器。
还有其他能加速将DNN推展到边缘运算的因素;例如CEA正在考量把神经网路架构本身调整为边缘运算的潜在可能。Duranton指出,现在人们已经开始讨论采用“SqueezeNet”架构而非“AlexNet”架构的神经网路,据了解,前者达到与后者相同精确度所需的参数规格是五十分之一;这类简单配置对于边缘运算、拓扑和降低MAC数量都十分关键。
而Duranton认为,最终目标是将经典DNN转换成“嵌入式”网路。
关键字:AI
编辑:冀凯 引用地址:http://www.eeworld.com.cn/manufacture/article_2016122812617.html |
|


 Allegro模仿PADS快捷键Z切换层L换层W改线宽
Allegro模仿PADS快捷键Z切换层L换层W改线宽 鸿蒙誓师大会:曙光在望,“待到山花烂漫时
鸿蒙誓师大会:曙光在望,“待到山花烂漫时 TI 12V汽车系统智能开关
TI 12V汽车系统智能开关 智能门锁触摸芯片_门锁感应芯片_指纹密码锁
智能门锁触摸芯片_门锁感应芯片_指纹密码锁 点阵段码驱动/I2C通讯接口VK2C21BA SSOP24
点阵段码驱动/I2C通讯接口VK2C21BA SSOP24 SPEED 2000 DDR Simulation VRM 生成问题
SPEED 2000 DDR Simulation VRM 生成问题 智能IC卡测试设备的技术原理和应用场景
智能IC卡测试设备的技术原理和应用场景 支付宝充值10元和微信充值50元没到账,能帮
支付宝充值10元和微信充值50元没到账,能帮 allegro羊皮卷
allegro羊皮卷 PADS和Allegro初级班开始报名了
PADS和Allegro初级班开始报名了 四轴飞行器
四轴飞行器 (兼容)正点原子 STM32F407 探索者原理图和P
(兼容)正点原子 STM32F407 探索者原理图和P 耐压绝缘测试仪的技术原理和应用场景
耐压绝缘测试仪的技术原理和应用场景 液晶驱动控制电路/段码LCD显示驱动芯片VK02
液晶驱动控制电路/段码LCD显示驱动芯片VK02 NT-PADS-第四期-项目二
NT-PADS-第四期-项目二 DRV8701 高达 30A 的直流电机驱动器 (AD)
DRV8701 高达 30A 的直流电机驱动器 (AD) 蓝牙协议分析仪的技术原理和应用场景
蓝牙协议分析仪的技术原理和应用场景 LCD显示驱动IC-VK0384 LQFP64液晶屏驱动芯
LCD显示驱动IC-VK0384 LQFP64液晶屏驱动芯 VK2C21A/B/C/D高抗干扰液晶驱动/LCD段码屏
VK2C21A/B/C/D高抗干扰液晶驱动/LCD段码屏 MOS管控制小板
MOS管控制小板





 发表于 2016-12-29 09:24:38
发表于 2016-12-29 09:24:38




")
")