TA的每日心情 | 擦汗
7 小时前 |
|---|
签到天数: 116 天 [LV.6]常住居民II
三级逆天
- 积分
- 81546
     
|
马上注册,结交更多好友,享用更多功能,让你轻松玩转社区
您需要 登录 才可以下载或查看,没有账号?立即注册
×
实际上,耳机是一个非常成熟的产业,全球一年市场销售量超过 3.3 亿对,每年维持稳定的成长。根据调研机构 Statista 预估,2016 年全球耳机销量约 3.34 亿对,预估 2017 年会成长到 3.68 亿对。其成长可以解释的成因除了真正无线(True Wireless)之外,再有的就是智能功能了。
同时,耳机产品也是一个相当分众的市场,追求音质的用户或是电竞玩家往往愿意付大钱购买具有高音质、立体声、高舒适度的产品,运动族群更在乎的则是防水、减少汗水或运动造成耳机掉落、或是具有生理量测的产品,另外也一群人是追求时尚、品牌而购买昂贵的耳机,例如 Apple 收购的 BEATS 。
不可否认的是,消费者可能每天会戴耳机听音乐,但不会每天都有跟外国人对话的需求,这让实时翻译成为一种有也不错而非必须性的附加性功能,因此耳机业者多会将其与更多功能结合,包括无线、智能语音助理等,因此实时翻译耳机虽后端整合了许多深度学习的技术,目前看来仍是话题性远高于实用性。
今年 Google 发表了一系列的硬件产品,其中 Pixel Buds 蓝牙耳机除了可以呼叫 Google Assistant 外,最吸睛的就是结合自家 Google 翻译可支持 40 种语言实时翻译的功能。
不久之前,韩国最大搜索引擎 NAVER 旗下的通讯软件 LINE 也推出 MARS 翻译耳机,对话的两个人各自使用一个耳塞,就能立即从耳机中听到翻译的语音,背后同样是仰仗自家的 AI 平台 Clova 及 Papago 即时翻译服务,目前可支持 10 种语言。
图|LINE 的 MARS 翻译耳机获得 CES 2018 最佳创新奖。(图片来源:LINE)
图|LINE 的 MARS 翻译耳机是一人使用一个耳塞,让说不同语言的两个人也能沟通。(图片来源:LINE)
总部位于深圳的耳机公司万魔(1more)声学海外事业部总经理陈颖达接受 DT 君采访时分析,耳机的新趋势就是真正无线(True Wireless Earbuds)蓝牙耳机+智能功能。在苹果推出 AirPods 之后,True Wireless 的趋势就确立下来了,音源与耳机或是左右耳的相通,完全不需要线路连接,跟过去蓝牙耳机的左右耳还是有线相连不同。
在智能功能方面有三大块,首先是支持生物识别运动追踪(biometric sports tracking)的运动耳机,例如可监测用户心率、计算运动过程中燃烧的卡路里等,市场需求看好;第二则是整合语音助理如 Apple Siri、Google Assistant ;第三就是实时翻译。
耳机的优势在于普及性及方便性,是启动个人化智能服务、翻译对话最直观的第一个入口,除了大企业,不少初创或音响公司都看好这块市场,例如德国品牌 Bragi 继推出防水(可于游泳使用)、测量心跳的产品,又进一步推出结合 AI 技术及 iTranslate 应用,可实时翻译的 The Dash Pro 耳机,另外英国的 Mymanu Clik 耳机也可支持 37 种语言即时翻译。
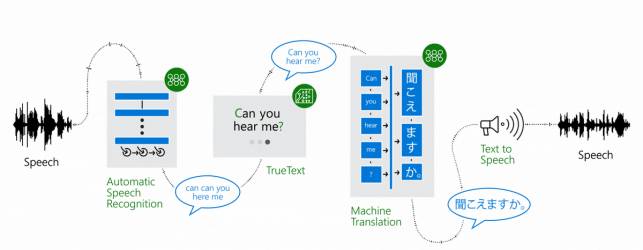
虽然说在市场层面还存在疑问,实时翻译耳机在技术上确实已经取得较大的进展。那么,这些强调利用 AI 技术的实时翻译耳机背后究竟是如何运作的呢?“三大核心:语音识别+机器翻译+语音合成,”台湾的中研院资讯科技创新研究中心副研究员曹昱清楚点出关键。
整个流程就是,耳机听到对方讲话的内容,识别出这是什么语言如英文、西班牙文等,并且把语音变成文字,第二步骤以翻译引擎进行文字对文字的翻译,最后就是把翻译结果做语音合成,播放出来。可以想成这是集合了听写员、翻译员、朗读员三个角色于一身。只不过,实际上每一个核心涉及的技术多且复杂。
图|实时翻译耳机三核心:语音识别、语言翻译、语音合成(图片来源:微软研究院)
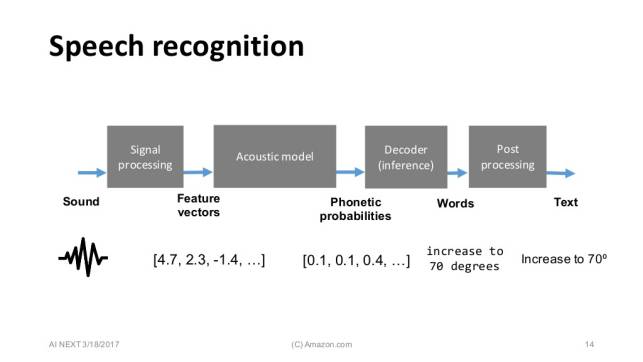
一、语音识别 首先使用的技术就是语音识别,Speech Recognition、自动语音识别(ASR,Automatic Speech Recognition)等都是常见的技术词汇,目的就是把说话者的语音内容转变为文字,目前多是以使用深度神经网络(DNN,Deep Neural Network)、递归神经网络(RNN,Recurrent Neural Network)为主。
图|语音识别的主要流程。(数据来源:Amazon)
语音识别的应用场景相当广泛,像是车内互动控制、智能助理、智能音箱、居家机器人等,主要的研究方向包括降噪、长距离识别等,目的都是为了提升识别度,例如居家机器人的问题就必须突破长距离语音识别的问题。
无线耳机有四个关键零组件:喇吧单体、麦克风、蓝牙晶片以及电池。一家外商声学公司对 DT 君表示,要支持实时翻译,麦克风就很关键,收音要够清楚,语音识别度才会高,在硬件上多会使用指向性麦克风,并且搭配语音识别算法,判断声音是来自讲话者或环境,进而强化人声,降低环境噪音的干扰。
过去语音识别主要是采用高斯混合模型(GMM,Gaussian Mixture Model)+隐马尔科夫模型(HMM,Hidden Markov Model)、支持向量机(SVM,Support Vector Machine)算法等,一直到神经网络之父 Geoffrey Hinton 提出深度信念网络(DBN,Deep Belief Network),促使了深度神经网路研究的复苏,并且将 DNN 应用于语音的声学建模,获得更好的表现,之后微软研究院也对外展示出利用 DNN 在大规模语音识别取得显著的效果提升,大量的研究陆续转向了 DNN,近来又有不少基于递归神经网络开发的语音识别系统,例如 Amazon Echo 就使用了 RNN 架构。
二、机器翻译从规则、SMT 走向 NMT 第二个阶段就是翻译,在人工智能中,机器翻译一直是许多人想突破的领域,概念就是通过分析原始语言(Source Language)找出其结构,并将此结构转换成目标语言(Target Language)的结构,再产生出目标语言。
初期多是采取把语言规则写进系统的方式,但这种以规则为主的机器翻译(RBMT,Rule-based Machine Translation)是将人类译者或是语言学家建构的词汇、文法、语意等规则写成计算机程序,但语言规则难以穷尽,而且例外、俚语也不少,除了耗费人力,翻译结果的准确性也遭人诟病,使得机器翻译的发展一度被打入冷宫。
到了 80 年代晚期,IBM 率先展开并提出统计式机器翻译(SMT,Statistical Machine Translation)理论,主要的研究人员 Peter Brown 、 Robert Mercer 等陆续发表《A Statistical Approach to Machine Translation》、《The Mathematics of Machine Translation: Parameter Estimation》论文,不仅被视为是该领域的开山之作,也再次引爆了机器翻译的热潮。
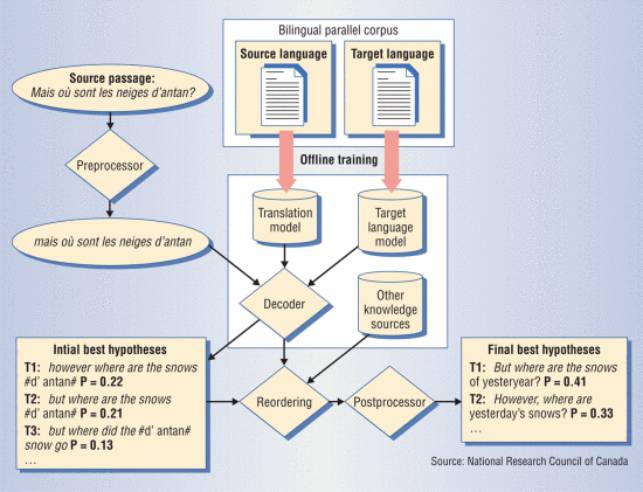
SMT 主要是通过搜集大量的原文与译文,通过统计模型让电脑学习字词的产生、转换、排列,形成合宜的句子,简单来说,例如 1000 句中文就有 1000 句英文进行对照,像是联合国有 6 种官方语言文件,加拿大政府的官方文件也有英文及法文,以及辞典,都是常被使用的素材。
不过,就在 SMT 火红了,并且成为机器翻译领域的主流技术之后,这两位专家却加入知名的量化基金公司 Renaissance Technologies,跑去华尔街用数学及统计模型分析股票、管理基金,变成了 10 亿美元级别的富豪。
“以机器翻译而言,20 年前 IBM 播种,20 年后 Google 收获”,台湾清华大学自然语言处理研究室教授张俊盛曾如此形容。
Google 翻译是目前全球拥有最多用户的翻译平台,2000 年初 Google 就开始投入机器翻译的研究,并且延揽了多位重量级人物协助开发,包括语音公司 Nuance 创始人 Michael Cohen 、知名机器翻译专家 Franz Och 等人。
最初负责领导整个 Google 翻译架构及服务开发的 Franz Och 曾表示,Google 翻译计划在 2001 年启动时只支持 8 种语言,速度很慢、品质不佳,到了 2006 年他们开始采用统计式机器翻译,并且同时利用大量的语料库作为训练。身为搜索引擎龙头,优势就是可通过网络搜集庞大的语料库、双语平行数据,提升机器翻译的水平。
图|统计式翻译的概念。(图片来源:National Research Council of Canada)
那时 Google 采用 SMT 中最普及的一个算法——片语为本的机器翻译(PBMT,Phrase-based Machine Translation),把一个句子切成多个单字(words)或短语(phrases)之后个别翻译。不过,这位 Google 翻译之父在 2014 年离开 Google 加入生医初创公司 Human Longevity,现则任职于癌症筛检初创公司 Grail。
但 Franz Och 的离开,并未对 Google 造成太大困扰,因为几年前 Google 就开始使用 RNN 来学习原文与译文之间的映射,到了 2016 年下旬 Google 正式发表翻译服务上线 10 年以来最大的改版,宣布转向采用类神经机器翻译(NMT,Neural Machine Translation),也就是现在大家耳熟能详的深度学习神经网络模型,以多层次的神经网络连结原文与译文,输出的字词顾虑到全句文脉,同时,也使用了大量 Google 自家开发的 TPU 来处理复杂运算,一举提升翻译的水平。
其实,利用深度神经网络进行机器翻译的概念在 2012、2013 年就被提出,DeepMind 研究科学家 Nal Kalchbrenner 和 Phil Blunsom 提出了一种端到端的编码器-解码器结构,“不过,一直到 Google 出了论文,用 NMT 取代 SMT,让大家完全相信神经网络在翻译是可行的,现在几乎所有公司都转向 NMT,我个人的想法是大概再三年机器翻译就可以达到人类翻译的水准”,专攻深度学习机器翻译的初创公司真译智能创办人吕庆辉如是说。
此后,NMT 成为了新一代机器翻译的主流,采用这种技术的服务在 2016 年下半年开始大量问世,Facebook 在今年 5 月也宣布将翻译模型从 PBMT 转向了 NMT。
Google 翻译产品负责人 Barak Turovsky 不久前接受媒体采访时表示:“SMT 是一种老派的机器学习(an old school machine learning)”,在网络上查找人类已经翻译过的内容,将其放进一个超大型的索引中,机器就开始看统计模式学习翻译。PBMT 的局限就在于必须把句子切成好几块,执行翻译时只能同时考量少数几个文字,而不是考虑上下文,所以如果要翻译的语言是属于不同语序结构,就会显得相当困难。
NMT 最大的突破就是它的运作方式类似于大脑,将一整个文句视为是一个翻译单元(unit),而非将文句切成好几块,这有两个优点,一是减少工程设计的选择,二是可依据上下文判断,提升翻译的正确性及流畅性,听起来会更自然。
在 NMT 技术中,除了递归神经网络(RNN)、卷积神经网络(CNN)、序列到序列(sequence-to-sequence)的长期短期记忆模型(LSTM,Long Short-term Memory)之外,近期的研究焦点包括了自注意力(Self-Attention)机制、以及利用生成式对抗网络(GAN,Generative Adversarial Networks)来训练翻译模型。
三、语音合成追求人类般的自然 实时翻译耳机的第三步骤就是语音合成(Speech Synthesis)或称为文本转语音(TTS,Text to Speech),也就是让电脑把翻译好的文字变成语音,并播放出来。重点在于如何生成更逼真的语音、更像人类说话的口气跟语调。
让电脑讲人话的企图心同样在很早期就出现,1970 年代就有了第一代的 TTS 系统,例如半导体公司德州仪器(TI)开发数字信号处理(DSP)芯片,还推出一个 Speak&Spell 玩具,会把打字的内容念出来,帮助小朋友学习。之后随着科技的进步,合成技术也从单音、片段变为可产生连续式的语音。
简单来说,要让电脑发出与人类相似的语音,通常会先录下人类或配音员说话,建立录音样本,再把单字切成音素(phoneme),并对录音进行分析,量测语调、速度等,建立语音模型,就可以制造出先前未录下的单字或句子。接着当文字输入,系统会选出适合的音素、音调、速度进行重组,再把这段文字转成语音播放出来,就像人说话一样。
图|TI 开发的 Speak&Spell 成为美国知名的玩具。(图片来源:Amazon)
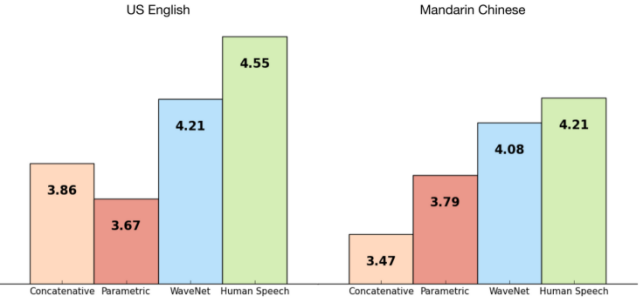
“目前语音合成技术应该就是 DeepMind 开发的 WaveNet 最自然”,曹昱指出。
语音合成以拼接式 TTS(concatenative TTS)为基础,需要大量的人类语音片段作为数据库,但如果想要转换为另一位说话者、或是加强语气或情绪,就必须重建新的数据库才能做到,使得修改语音的难度很高。
因此,出现了另一种参数式 TTS(parametric TTS),产生数据所需的所有信息都被存储在模型的参数之中,只要通过模型的输入值,就能控制语音的内容和特色,再把输出值丢到语音编码器(Vocoders)来产生声音,是一种完全由机器生成的语音,优点是成本较低,缺点则是机械味较重。
而 WaveNet 使用 CNN 架构,同样是拿人类说话作为训练素材,但不像拼接式 TTS 把声音切成许多片段,而是使用原始波形,而且为了让声音更逼真,也必须告诉机器文本(text)内容是什么,所以也将把文本转换为语言或语音特征喂给机器,“不仅要考虑以前的音频样本,还要靠虑文本内容”,所以还可以做出像人类讲话时的口气停顿或是呼吸的声音。这些都让 WaveNet 的语音合成更有“人味”,今年 10 月 Google 宣布把最新版本的 WaveNet 放到美式英文版以及日文版的 Google Assistant 中。
图|DeepMind 开发的 WaveNet 提高了语音合成的逼真度。(图片来源:DeepMind)
随着深度学习技术的发展,不论是在语音识别、机器翻译、还是语音合成,都可看到应用水平已有所提升,不过,实时翻译耳机的实际应用仍无法满足所有人,举例来说,Google Pixel Buds 的翻译功能只限于 Pixel 2 手机使用,而且要一句一句说,还无法提供连续性的翻译,例如当你想要用它来看外国电影,这个方法就行不通。
另外,Pixel Buds 的麦克风收取使用者的声音,然后通过手机大声说出翻译,对有些人还是会感到有一些尴尬。而 LINE 的 Mars 耳机是让对话的两人各戴一个耳塞,翻译的内容只有自己听得到,看似可以解决这个尴尬问题,但实际效果如何还得待 2019 年上市后才知道。
虽然实时翻译耳机还不够完美,是否能够通过市场的检验还未可知,但要往零阻碍沟通的方向前进,AI 无疑将扮演重要的角色。 |
|


 再发某公司的PADS格式 PCB封装库全套共享
再发某公司的PADS格式 PCB封装库全套共享 Allegro超强最全模仿PADS快捷键实现Z切换层
Allegro超强最全模仿PADS快捷键实现Z切换层 RK3576+GSV6127+LT7911C+ADV7180+ALC5640
RK3576+GSV6127+LT7911C+ADV7180+ALC5640  IR2104+6N137+LM2940+MAX761+IRF3205 做的
IR2104+6N137+LM2940+MAX761+IRF3205 做的 Lattice LFE5UM-85F-6BG381C 核心板PCB文
Lattice LFE5UM-85F-6BG381C 核心板PCB文 ASL CS5261:高性能Type-C转HDMI转换芯片
ASL CS5261:高性能Type-C转HDMI转换芯片 UCC28810D 做的 120W LED电源板PCB和原理图
UCC28810D 做的 120W LED电源板PCB和原理图 allegro羊皮卷
allegro羊皮卷 4个 PEX8764 做的大型工业主板PCB文件 18层
4个 PEX8764 做的大型工业主板PCB文件 18层 高抗干扰触控芯片/3路触摸触控IC/触摸感应
高抗干扰触控芯片/3路触摸触控IC/触摸感应 Allegro软件中各个约束规则管理模式的具体
Allegro软件中各个约束规则管理模式的具体 Allegro软件中热风焊盘的作用是什么
Allegro软件中热风焊盘的作用是什么 Allegro软件中检查单端网络
Allegro软件中检查单端网络 Allegro软件中快速的交换两个器件
Allegro软件中快速的交换两个器件

 发表于 2017-12-18 10:42:09
发表于 2017-12-18 10:42:09




")
")