TA的每日心情 | 衰
2024-10-6 20:55 |
|---|
签到天数: 1 天 [LV.1]初来乍到
二级逆天
- 积分
- 2115
 
|
马上注册,结交更多好友,享用更多功能,让你轻松玩转社区
您需要 登录 才可以下载或查看,没有账号?立即注册
×
[paragraph]深鉴科技发明的人工智能芯片,结合了神经网络专用处理器和通用处理器的芯片结构,不仅可以提供一个灵活的系统,并且可以适用于复杂的神经网络。
近年来,随着人工智能领域的兴起,越来越多的AI芯片公司出现在了人们的视野之中,AI芯片被广泛应用于金融、购物、安防、早教以及无人驾驶等领域。而这其中,深鉴科技也凭借着先进的技术在市场中崭露头角。
深鉴科技的AI芯片基于FPGA设计,其设计的亚里士多德架构是针对卷积神经网络而设计的,其设计的笛卡尔架构是专为处理DNN/RNN网络而设计的,可对经过结构压缩后的稀疏神经网络进行极致高效的硬件加速。
在人工智能领域,卷积神经网络尤其在图像处理领域有着非常广泛的应用,其具有训练方法简单、计算结构统一的特点。但是神经网络存储计算量都很大。工程师们试图在FPGA上搭建或者直接设计专用芯片来实现人工智能芯片,但是,这种专用神经网络加速器的硬件还是不够灵活,且能够完成的任务较为单一。
为了解决这样的问题,深鉴科技在16年8月19日申请了一项名为“通用处理器与神经网络处理器的协同系统设计”的发明专利(申请号:201610695285.4),申请人为北京深鉴科技有限公司。
根据该专利目前公开的资料,让我们一起来看看这项人工智能芯片专利吧。
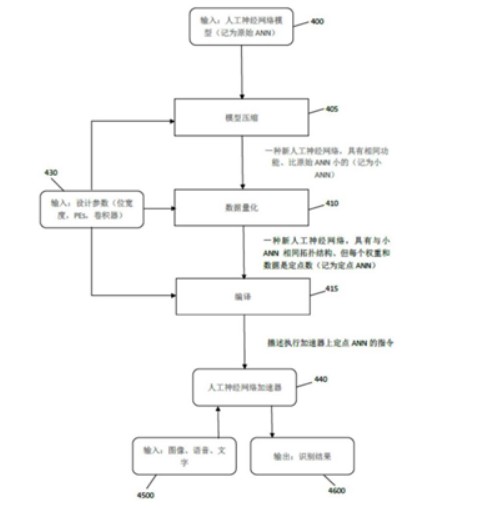
如上图,为把人工神经网络模型部署在专用硬件上的流程示意图,这是一套为了加速神经网络训练过程,从优化流程的硬件架构的角度提出了一整套的技术方案,其中显示了如何压缩CNN模型以减少内存占用和操作数量,同时最大限度地减少精度损失。
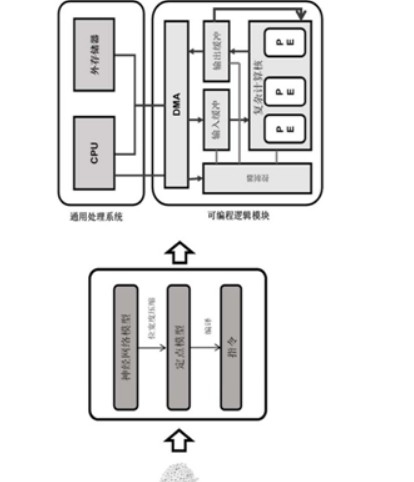
这种硬件架构包括PS和PL两个模块,其中:PS为通用处理系统,其中包含有CPU和外部存储器;PL为可编程逻辑模块,其中包含有DMA、计算核、输入输出缓冲以及控制器等。计算核包括多个处理单元,其负责在人工智能网络的卷积层以及全连接层的大多数计算任务,是实现人工智能芯片的核心部件。
值得一提的是,在这种架构中,虽然DMA分布在PL一侧,但是却直接被CPU所控制,并且将数据从外部存储区内搬运到PL中。同时,这种硬件架构仅仅是进行了功能上的划分,PL和PS之间的界限并不绝对,例如PL和CPU都可以仅仅实现在SOC上,而外部存储器可以由另一个存储器芯片实现并于SOC芯片中的CPU相连接。
如上图为优化人工神经网络的整体流程图,首先要对于模型进行压缩,压缩可以对CNN模型进行修剪,而网络修剪是一种有效的方法,可以减少网络的复杂性和过度拟合。其次,进行数据定点量化,目的是为了将浮点数转换为定点数的同时得到最高精度。
之后再通过编译,通过这样的结构设计得到人工神经网络加速器,从而可以做到输入图像、语音、文字,即可输出识别的结果。这样进行精简后的结构有利于硬件设计,同时省去了较为复杂的运算,进一步提高了人工智能芯片进行运算的效率。
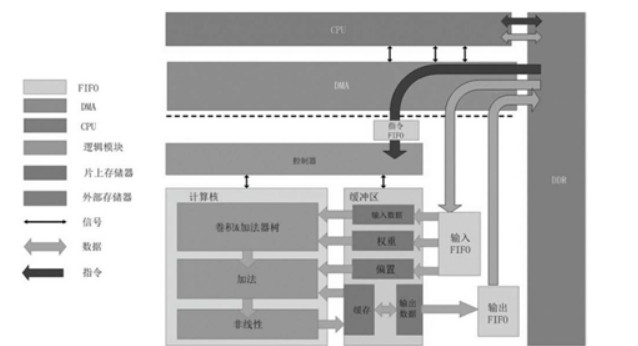
如上图,为使用CPU和专用加速器的协同设计来实现人工神经网络的硬件架构,在这种硬件架构中,CPU控制DMA,由DMA来负责调度数据,具体而言,CPU可以控制DMA将外部存储器中的指令搬运到FIFO(缓冲器)中,随后,这种为神经网络设计的加速器从FIFO中取出指令并执行。
在运行的时候,CPU需要时刻监控DMA的状态:当输入缓冲区的数据未满时,需要把数据从DDR中搬运到输入缓冲区中;当输出缓冲区不为空时,需要将数据从输出缓冲区中搬运回DDR中。
此外,这种结构中使用的专用加速器包括:控制器、计算核以及缓冲区,计算核包括卷机器、加法器树和非线性模块,这些结构保证了人工智能芯片完成深度神经网络的运算,从而可以完成不同的复杂的人工智能任务。
以上就是深鉴科技发明的人工智能芯片,这种结合神经网络专用处理器和通用处理器的芯片结构,可以为人工智能应用提供一个灵活的系统,并能够适用于复杂的神经网络。并且该方案实现了控制器与存储器的分离,控制器和存储器可以使用不同的SOC芯片完成,进而保证了系统的稳定性。
关于嘉德深圳市嘉德知识产权服务有限公司由曾在华为等世界500强企业工作多年的知识产权专家、律师、专利代理人组成,熟悉中欧美知识产权法律理论和实务,在全球知识产权申请、布局、诉讼、许可谈判、交易、运营、标准专利协同创造、专利池建设、展会知识产权、跨境电商知识产权、知识产权海关保护等方面拥有丰富的经验。
责任编辑:tzh |
|


 再发某公司的PADS格式 PCB封装库全套共享
再发某公司的PADS格式 PCB封装库全套共享 Allegro超强最全模仿PADS快捷键实现Z切换层
Allegro超强最全模仿PADS快捷键实现Z切换层 HDMI TO VGA dongle(CH7101A+RT8008+HDMI_A
HDMI TO VGA dongle(CH7101A+RT8008+HDMI_A EP94Z1E HDMI转VGA方案
EP94Z1E HDMI转VGA方案 6声道单面功放板PADS9.5
6声道单面功放板PADS9.5 TMP86CH49车载导航主板PCB
TMP86CH49车载导航主板PCB BC04 USB蓝牙发射器
BC04 USB蓝牙发射器 allegro羊皮卷
allegro羊皮卷 MS8188运算放大器可兼容ADA4522/MAX44244/T
MS8188运算放大器可兼容ADA4522/MAX44244/T RK3576资料分享
RK3576资料分享 笔段式液晶显示屏驱动VKL128 LQFP44低功耗L
笔段式液晶显示屏驱动VKL128 LQFP44低功耗L 数字存储示波器的原理和应用
数字存储示波器的原理和应用 4键触摸芯片/低功耗4路触控/触摸感应IC-VKD
4键触摸芯片/低功耗4路触控/触摸感应IC-VKD 单片机原理及应用.pdf
单片机原理及应用.pdf

 发表于 2020-10-27 09:14:09
发表于 2020-10-27 09:14:09












")
")