|
|
马上注册,结交更多好友,享用更多功能,让你轻松玩转社区
您需要 登录 才可以下载或查看,没有账号?立即注册
×
狭路相逢——篇二
上篇也是ARM和X86的简述,涉及的技术很少,如有历史差错欢迎更正。
ARM和Intel X86原本都在各自的道路上发展前进,ARM处理器的优势一直是低功耗,专注于发展32位架构,在移动端称霸,让Intel眼馋。而在PC和服务器领域,Intel的市场也让ARM眼红,也不断有市场摩擦,但终究还是抵挡不住市场的诱惑。2008年,Intel推出了Atom处理器移动端,试水移动设备。而ARM随着市场份额不断扩大,在面向企业级领域的时侯,其发现并没有64位架构处理器,于是在2012年10月31日ARM推出新款ARMv8架构Cortex-A50处理器系列产品,来满足企业级级市场应用的需求。这样直接就和Intel的PC服务器市场相逢。
指令集架构ISA
An instruction set architecture (ISA, 指令集架构) 是计算机的抽象模型,也称体系结构或计算机体系结构。ISA允许多种实现,不通实现的性能,物理尺寸和成本会有所不同。早期的程序员都是汇编实现,汇编直接打交道的就是这些指令集,所以ISA也是软件和硬件之间的接口。
为一个ISA编写的软件可以在同一ISA的不同实现上运行。这使得可以轻松实现不同代计算机之间的二进制兼容性以及计算机家族的发展。
指令集体系结构与微架构结构不同,微架构是在特定处理器(每个CPU都有自己的微架构)中用于实现指令集的一组处理器设计技术,ISA 的“实现”需要借助各种微架构。不同微体系结构的处理器可以共享一个公共指令集。例如Intel Pentium和AMD Athlon实现了几乎相同的x86指令集版本,但是内部微架构却大相径庭。
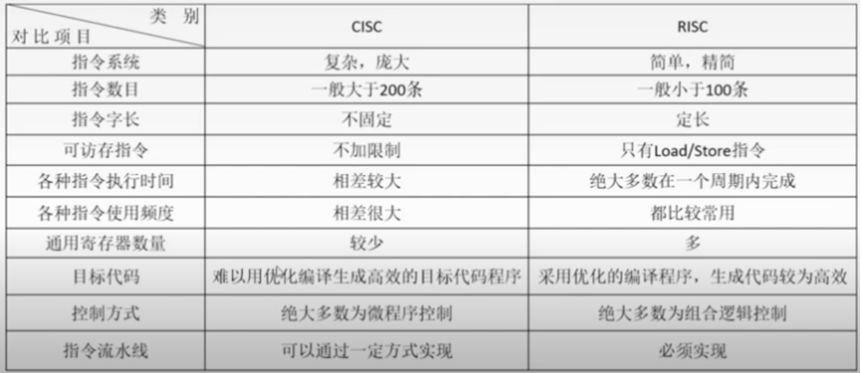
精简指令集RISC(Reduced Instruction Set Computer)和复杂指令集CISC(Complex Instruction Set Computer)的区分是从上个世纪70年代开始的,IBM研究关于CPU如何高效的运行,发现有些常用的指令占比很高。20%的指令完成了80%的工作。
于是就琢磨如何把CPU从硬件上设计简单一点,从而使得软件上高效一点,这样就提出了精简指令集这个概念,其最大的特点就是它的指令宽度是相等的,每个指令执行的周期几乎也相同,这样把复杂的指令简单化,最后用简单的操作去完成一件复杂的任务。
而复杂指令集(CISC)每一个指令的长度是不同的,导致机器码、指令码不同,导致每条指令的执行周期不同,从而使得软件流水操作上处理的步骤不一样的。这样的一个好处是一个指令就能完成一个比较复杂的事情,对上层的程序员来讲,会容易理解一些,特别是汇编程序员。
我们来看下RISC和RISC的各自特点。
RISC(Reduced instruction set computer)
RISC精简指令集计算机,其关键特征是指令编码格式统一,相比CISC,RISC需要叫CISC一声大哥。
因为早期的微处理器大部分为复杂指令集(CISC)架构,在设计中尽可能复杂的指令来完成任务,主要因素是当时的编译技术限制,同时可让汇编程序员更加方便的编程。
随着编译器技术及其他技术的不断发展,以及发现多数的复杂指令只在很少的时候被用到,另外复杂的指令限制了处理器速度的进一步提高。在这样背景下,精简指令集(RISC)技术应运而生。IBM 801应该是第一个用精简指令集的理念来设计的系统,并发展成为了今天的Power架构(IBM小型机神话)。RISC架构下也诞生了SPARC/MIPS等各种RISC处理器,一时间也是百花争鸣。
RISC特点
RISC的主要特点如下:
[li]简单、基本的指令:通过简单、基本的指令,组合成复杂指令。[/li][li]同样长度的指令:每条指令的长度都是相同的,可以在一个单独操作里完成。[/li][li]单机器周期指令(易流水线):大多数的指令都可以在一个机器周期里完成,并且允许处理器在同一时间内执行一系列的指令。便于流水线操作执行。[/li][li]更多的通用寄存器:例如ARM处理器具有31个通用寄存器。大多数数据操作都在寄存器中完成[/li][li]寻址方式简化:由于指令长度固定,指令格式和寻址方式种类减少。[/li][li]Load/Store结构:使用load/store指令批量从内存中读写数据,数据传输效率高;[/li][li]体积小,低功耗,低成本;[/li] 从RISC的特点,我们可以得到RISC体系的优缺点,其实当前很多底层技术相互之间在不断融合,所以以下也只能参考了:
优点:在使用相同的芯片技术和相同运行时钟下,RISC 系统的运行速度将是 CISC 的2~4倍。由于RISC处理器的指令集是精简的,所以内存管理单元、浮点单元等都能更容易的设计在同一块芯片上。RISC处理器比相对应的 CISC处理器设计更简单,开发设计周期更短,可以比CISC处理器应用更多先进的技术,更快迭代的下一代处理器。
缺点:更多指令的操作使得程序开发者必须小心地选用合适的编译器,编写的代码量会变得非常大。另外RISC体系的处理器需要更快的存储器,这通常都集成于处理器内部(现在处理器当前都有CACHE的)。
ARM指令集
ARM指令集作为RISC架构体系的具体实现,继承了RISC架构的所有特点。
由于是精简指令集,ARM中的复杂工作便需要由编译器(compiler) 来执行实现,而 CISC 体系的X86指令集因为硬体所提供的指令集较多,许多工作能够以一个或是数个指令来代替,可以有效减少编译器的工作。
ARM指令集除了具备上述RISC的诸多特性之外,还支持Thumb指令集,能很好的兼容8位/16位器件来提高代码密度;目的是在低端或者入门市场应用中改善 ARM 的指令密度(可减少大约 25%~35% 代码空间);cache 中塞入更多的指令以减少命中缺失,更高密度的指令编码也有利于多线程因为可用寄存器资源更多了。同时也扩展了条件执行指令来提高代码密度和性能。
此外,ARM也引入了一些非RISC指令架构的思想的(其实X86处理器也在不断引入RISC架构思路)如:允许一些特定指令的执行周期数字可变,以降低功耗,减小面积和代码尺寸; 增加了移位器来扩展某些指令的功能; 使用增强指令来实现数字信号处理的功能等等。
总体上,ARM处理器最大的特点在于节能,这也是其在移动通信领域无人能敌的原因之一。但是随着面临企业数据中心时候,为了进一步追求高性能,其节能设计相信定会慢慢淡化。
ARM指令集进化
在基于原有的原则和指令集上,ARM公司开发一个简明的64位架构ARMv8,该架构同时使用了两种执行模式,AArch32和AArch64。ARM处理器在运行中可以无缝地在两种模式间切换。这意味着64位指令的解码器是全新设计的,不用兼顾32位指令,而处理器依然可以向后兼容。
ARMv8架构上也引入了浮点单元协处理器扩展VFP(Vector Floating Point,向量浮点),提供了完全遵循 IEEE 754-1985 的低成本单精度和双精度浮点支持。虽然 VFP 打着向量的名头,不过这些“向量”指令的各个向量是串列方式执行(或者需要单精度搭配双精度才能实现并行执行)的,并不能提供真正的 SIMD 向量并行,因此这个向量模式被拿掉了。
Advanced SIMD(NEON)扩展在微架构实现中被称作 MPE(媒体处理引擎),是一个 64-bit 和 128-bit SIMD 指令集扩展,支持 8/16/32/64 位整数和 32-bit 单精度浮点数,共享使用 VFP 的寄存器。从 ARMv8 开始,NEON 在 AArch 64-bit 模式下提供完全遵循 IEEE 754 和双精度支持并且透过 VFPv4 具备 32 个 128-bit 寄存器。
ARM的关键技术跃迁如下图:
ARM的异构
在ARM架构中,有项技术是Intel至今没有复制的。就是ARM的big.LITTLE架构。在big.LITTLE架构里,在同一个处理器中的核可以是不同类型的。而在Intel 双核Atom处理器中,其两个是一模一样的核,提供一样的性能,拥有相同的功耗。但是ARM通过big.LITTLE推出了异构计算,双核ARM处理器中的核可以有两个完全不同的性能和功耗,当设备正常运行时,使用低功耗核,而当运行一款复杂的游戏时,使用的是高性能的核。
具体一点,例如ARM Cortex-A53采用顺序执行,因此功耗低一些;而ARM Cortex-A57使用乱序执行,更快但更耗电。采用big.LITTLE架构的处理器可以同时拥有Cortex-A53和Cortex-A57核,系统可以根据具体的需要决定如何使用这些核。这个是不是很赞。
关于华为海思ARM授权
目前华为海思已经获得了 ARMv8 架构的永久授权 (ARMv8 是 ARM 公司的 32/64 位指令集)。华为有可能也有能力进行完全自主设计 ARM 处理器,并掌握核心技术和完整知识产权,具备长期自主研发 ARM 处理器的能力。这个需要我们拭目以待。到目前为止,ARMv9架构已经发布,华为海思应该还没有拿到授权,未来华为海思需要根据自己设计开发兼容ARMv9的微架构处理器了。
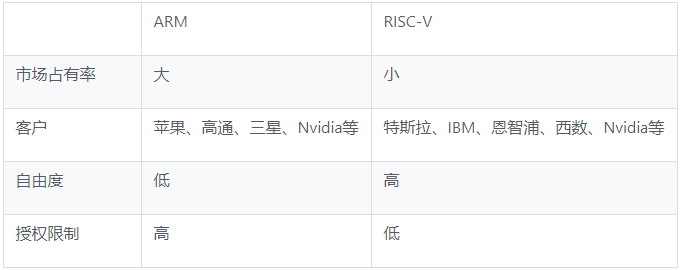
RISC-V
说到RISC架构,我们这里不得不提到RISC-V架构。
在2010年左后,Berkeley的Krste Asanovic 教授想要为未来系列项目选择一个微处理器指令集,但没有找到他自己满意的。Intel的X86是CISC指令集,过于复杂和庞大,且存在专利问题。而ARM除了专利问题外,若想自行设计基于ARM指令集的处理器,需要非常昂贵的License。而OpenRISC发展缓慢,设计老旧,64位架构也不成熟。
就这样,Krste教授决定带领团队重新开发一个完全开放的、标准的、能够支持各种应用的新指令集(得到了RISC的发明者之一Dave Patterson教授的大力支持)。大约花了四年的时间,终于开发了一套完整的新的指令集,同时也包含了移植好的编译器、工具链、仿真器,并经过了数次流片验证。这个新的指令集叫做RISC-V,"V"包含两层意思,一是这是Berkeley从RISC I开始设计的第五代指令集架构,二是它代表了变化(variation)和向量(vectors)。
2015年12月的Nature网站上,Berkeley等几个大学的研究人员主导的开发团队发表了一篇文章,描述了用标准的CMOS工艺制造了同时集成了RISC-V指令集的CPU。
关于RISC-V指令集
RISC-V指令集由一个非常小的基础指令集和一系列可选的扩展指令集。最基础的指令集只包含40条指令,通过扩展还支持64位和128位的运算以及变长指令,扩展包括了乘除运算、原子操作、浮点运算等,以及开发中的指令集包括压缩指令、位运算、事务存储、矢量计算等。指令集的开发也遵循开源软件的开发方式。
RISC-V架构精简,现阶段已经可以对应执行64位元运算模式,相比ARM Cortex-A5架构设计的处理器,RISC-V架构打造的处理器约可在运算效能提升10%,并且在占用面积精简49%,用于嵌入式装置可带来不少竞争优势。
在商业授权方面,通过指令集扩展,任何企业都可以构建适用于任何领域的微处理器,比如云计算、存储、并行计算、虚拟化/容器、MCU、应用处理器、DSP处理器等等。目前Berkeley开发了多款开源的处理器,可覆盖从高性能计算到嵌入式等应用领域,并孵化出了初创公司SiFive并获得了风投。
此外开源硬件树莓派(Raspberry Pi)的创始人之一罗伯特·穆林斯(Robert Mullins)创建了lowRISC,基于RISC-V开发一款真正的开源处理器芯片,以代替目前树莓派上的由博通开发的非开源处理器。
2016年初的Workshop上RISC-V基金会成立,成员包括Google、惠普、Oracle、西部数据等硅谷巨头,运用RISC-V到云计算设施或者智能手机芯片中,可以摆脱对X86的依赖或是减少昂贵的ARM指令集授权费用。
虽然,目前RISC-V的生态还处于初级阶段,但由于大量的科技业巨头进驻RISC-V基金会,生态建设只是时间问题(中国的处理器由于没有历史包袱,从头开始建立互相兼容的RISC-V生态可能是天赐良机)。
Western Digital将以RISC-V架构打造储存设备控制器,而NVIDIA计划将RISC-V架构用于GPU内部控制元件,也有不少新创团队开始透过RISC-V架构设计物联网设备使用芯片,软件方面也陆续加入JVM、LLVM、Python等常见开发工具。
RISC-V目前主要是布局大数据、人工智能等领域,从ARM和X86尚未完全占领的市场起步。以目前RISC-V在业界掀起的巨大波澜来看,将来很可能足以挑战x86和ARM的地位。
RISC-V和ARM
由于长期饱受ARM授权费之苦,天下苦ARM久矣。只要RISC-V时机成熟,相信典型的ARM下游企业苹果、谷歌和高通三家公司一定反水,而其他的下游公司那就都是墙头草了,大佬用什么我们用什么。
从目前来看,RISC-V的诞生对基于CISC的x86影响相对较小。因为CISC和RISC应用之争基本泾渭分明。CISC适合于强调运算和性能的场景,如电脑、数据存储等领域,RISC 则主要针对特殊应用领域,适合对功耗比要求更高的专用领域,如移动设备。
RISC-V指令集架构未来可能会成为ARM和x86的可行替代方案,但目前来看来主要还是对同属RISC阵营的ARM影响巨大。虽然目前还没有基于RISC-V的芯片量产,但是ARM在以后日子肯定会有芒刺在背的感觉。
所以,ARM公司未来最大敌人可能就是来自的同阵营(RISC)的RISC-V这个开源解决方案。
CISC(Complex instruction set computer)
复杂指令集(CISC)是伴随着计算机诞生便存在的指令集,拥有较强的处理高级语言的能力,对于提高计算机性能有一定好处。但是日趋复杂的指令系统带来了效率的低下,使系统结构的复杂性增加,也将导致了CISC的通用性不佳。从指令集架构来看,Intel也承认,CISC架构确实限制了CPU的发展。
CISC体系的指令特征如下,
[li]使用微代码,指令集可以直接在微代码存储器(比主存储器的速度快很多)里执行。[/li][li]庞大的指令集,可以减少编程所需要的代码行数,减轻程序员的负担。包括双运算元格式、寄存器到寄存器、寄存器到存储器以及存储器到寄存器的指令。[/li] 指令特征也直接显现了CISC体系的优缺点:
优点:可有效缩短新指令的微代码设计时间,允许设计师实现 CISC 体系机器的向上兼容。新的系统可以使用一个包含早期系统的指令超集合。另外微程序指令的格式与高级语言相匹配,因而编译器并不一定要重新编写。
缺点:指令集以及芯片的设计比上一代产品更复杂,不同的指令,需要不同的时钟周期来完成,执行较慢的指令,将影响整台机器的执行效率。
X86指令集
X86指令集是Intel为第一块16位CPU(8086)开发的,后为提高浮点数据处理能力而增加的X87芯片系列数学协处理器以及使用X87指令,后来就将X86指令集和X87指令集统称为X86指令集。
Intel X86系列及其兼容CPU都使用X86指令集,形成了如今庞大的X86系列及兼容CPU阵容。
目前X86指令集通用寄存器组(CPU的内核)有16个通用寄存器(rax, rbx, rcx, rdx, rbp, rsp, rsi, rdi, r8, r9, r10, r11, r12, r13, r14, r15),与ARM的31个通用寄存器比起来是少了近一半。X86 CPU复杂指令执行时大多数时间是访问存储器中的数据,会直接拖慢指令执行速度。
X86处理器特有解码器(Decode Unit),把长度不定的x86指令转换为长度固定的类似于RISC的指令,并交给RISC内核。解码分为硬件解码和微解码,对于简单的x86指令只要硬件解码即可,速度较快,但复杂的x86指令则需要进行微解码,并把它分成若干条简单指令,速度较慢且很复杂。X86指令集严重制约了性能表现。
x86 需要将一些工位拆开(这意味着流水线工位更多或者流水线长度更深)。流水线设计可以让指令完成时间更短(理论上受限于流水线执行时间最长的工位),因此将一些工位再拆开的话,虽然依然是每个周期完成一条指令,但是“周期”更短意味着指令吞吐时间进一步缩短,每秒能跑出来的指令数更多,这就是超级流水线的初衷。
32到64位X86指令集扩展纷争
Intel在很早就想做64位架构处理器,但是如果从已有的32位x86架构进化出64位架构,那么新架构效率会很低,于是与惠普一起搞了一个新64位处理器项目名为IA64(即安腾)(基于显式并行指令计算(Explicitly Parallel Instruction Computing)EPIC,相比CISC和RISC架构,每个时钟周期能够处理大约8倍的计算任务),诞生了Itanium系列处理器,由于生态等原因,除了一些存量机器运维,其他软硬件在Itanium投入都已经彻底放弃了。
Intel本来想抛弃兼容性的包袱,没想到为了Itanium需要抛弃了自己成功的基础,两害相侵取其轻,最后不得不放弃Itanium。
因为AMD知道自己造不出能与IA64兼容的处理器,于是它把x86扩展一下,加入了64位寻址和64位寄存器。最终出来的架构,就是 AMD64,成为了64位版本的x86处理器的标准。这一次AMD又交了一个满分答卷。
X86架构中的RISC思想
大量的复杂指令、可变的指令长度、多种的寻址方式这些是CISC的特点,也是启缺点。因为这都大大增加了解码的难度,在现在的高速硬件发展下,复杂指令所带来的速度提升已不及在解码上浪费的时间。而RISC体系的指令格式种类少,寻址方式种类少,大多数是简单指令且都能在一个时钟周期内完成,易于设计超标量与流水线,寄存器数量多,大量操作在寄存器之间进行,其优点是不言而喻的。
Intel似乎也将最终抛弃x86而转向RISC结构,而实际上,传统的X86系列处理器在Intel公司的积极改进下,原来认为是CISC体系结构的X86处理器也吸收了许多RISC的优点,例如Pentium处理器在内部的实现中也是采用的RISC的架构,复杂的指令在内部由微码分解为多条精简指令来运行,但是对于处理器外部来说,为了保持兼容性还是以CISC风格的指令集展示出来。X86处理器也克服了功耗过高的问题,成为一些高性能嵌入式设备的最佳选择。
另一方面,而RISC自身的设计中为了追求性能也正在变得越来越复杂(当然并不是完全依着CISC的思路变复杂)。
所以我们发现RISC和CISC也开始出现了技术融合,这也导致他们的市场也出现了交集,因为它们也已经不是曾经单纯的“它们”了。
Intel X86指令集并不是因为一开始就在技术上的绝对优势,而是其先取得了生态优势(和金钱优势),然后不断投入技术研发,从而让X86处理器取得了绝对的性能优势。ARM回归服务器市场和intel正面较量,也是其赚到钱后来自资金的底气,可以不断投技术研发并快速迭代来争抢企业数据中心市场蛋糕。所以,RISC(ARM)和CISC(X86)最后要在PC服务器市场会有一场终局之战了。
ISA细化差异小结
这个小结其实是教条式的参考,如上小节所说,技术本身也在不断演化,总会渐渐的变得那么“不单纯”。
RISC通过精简指令达到简化处理器结构的目的。理论上采用RISC的处理器在功耗上要低于CISC,RISC采用硬布线技术理论上性能也会高于微程序的CISC。RISC理论上是对CISC的简化和优化。
目前,CISC和RISC在设计过程中也开始相互借鉴思路,造成了目前RISC和CISC不分高低的局面。
从理论上两者差距如下:
总体上来看:
执行时间和空间:CISC 因指令复杂,故采用微指令码控制单元的设计,而RISC的指令90%是由硬件直接完成,只有10%的指令是由软件以组合的方式完成,因此指令执行时间上RISC较短,但RISC所须ROM空间相对的比较大。
寻址方面:CISC的需要较多的寻址模式,而RISC只有少数的寻址模式,因此CPU在计算存储器有效位址时,CISC占用的周期较多。
指令的执行:CISC指令的格式长短不一,执行时的周期次数也不统一,而RISC结构刚好相反,适合采用流水线处理架构的设计,进而可以达到平均一周期完成一指令。
设计上:RISC较CISC简单,同时因为CISC的执行步骤过多,闲置的单元电路等待时间增长,不利于平行处理的设计,所以就效能而言RISC较CISC还是占了上风,但RISC因指令精简化后造成应用程式码变大,需要较大的存储器空间。
RISC是为了提高处理器运行速度而设计的芯片设计体系,关键技术在于流水线操作(Pipelining):在一个时钟周期里完成多条指令。目前,超流水线以及超标量设计技术已普遍在芯片设计中使用。
而ARM的优势不在于性能强大而在于效率,ARM采用RISC流水线指令集,在完成综合性工作方面可能就处于劣势,而在一些任务相对固定的应用场合其优势就能发挥得淋漓尽致。
关于功耗设计
这里我们加入了功耗设计一节,主要是稍微探讨一下处理器功耗的原因。这样我们就能理解为什么服务器中ARM处理器的功耗也不低。因为追求性能必定会引入过高的功耗。
工艺与功耗
和功耗直接相关的是工艺制程。
目前7nm的ARM的处理器当前主要是靠台积电等专业制造商生产的,而Intel是有自己的工厂制造的。如果同样的设计,工艺越先进功耗越低这个是毫无疑问的。
但是同时,功耗不只是一个工艺制程的问题,随着复杂部件的增多,例如乱序并发,分支预测等部件的增加,都会直接影响到功耗,也就是说设计直接影响功耗。
设计与功耗
处理器设计可以分为前端和后端设计,前端设计是处理器的构架,例如我们提到的精简指令集和复杂指令集。后端设计处理电压,时钟等问题,是耗电的直接因素。
处理器的耗电问题,其实就是晶体管的耗电,就像我们耗电问题说到底就是家里的电器耗电一样。晶体管耗电主要两个原因,一个是动态功耗,一个是漏电功耗。
动态功耗是指晶体管在输入电压切换的时候产生的耗电,而所有的逻辑功能的0/1切换,就是是时钟信号的切换。如果时钟信号保持不变,那么这部分的功耗就为0,就是门控时钟(Clock Gating)。
而漏电功耗是可不避免的,只能通过关掉某个模块的电源来控制(Power Gating)来关闭。但是这会使得时钟和电源所控制的对应模块无法工作。门控时钟的恢复时间较短(动态功耗),而电源控制的模块恢复时间较长(漏电功耗)。如果某单条指令使用多个模块的功能,在恢复该指令功能的时候,恢复时间可能是几个模块时间的相加,因为这牵涉到上电次序(Power Sequence)的问题,恢复工作时候模块间是有先后次序的,不遵照次序是无法恢复。而遵照这个次序,就会使得总恢复时间很长。所以在后端,为了省电可以关闭一些暂时不会用到的处理器模块;但又不能轻易关闭,否则一旦需要,恢复某个指令的时间会很长,总体性能显著降低。此外,关于子模块的开关通常是设计电路时就决定的,这个对于操作系统是透明的,无法通过软件来优化。
X86为了保持高性能,使用乱序执行,这样会让大部分的模块都保持开启,并且时钟也保持切换,直接后果就是耗电高。而ARM的指令确定执行顺序(移动设备),并且依靠多核而不是单核多线程来执行,容易保持子模块和时钟信号的关闭,显然就会更省电一点(当然目前ARM也是支持乱序的)。
功耗小结
随着ARM进入服务器领域,其处理器中的前后端设计也随着复杂化,原本在移动端领域的功耗的优势,在服务器领域并不明显存在了。
设计处理器的时候,要考虑大量的技术设计的采用与否,这些技术设计决定了处理器的性能以及功耗。在一条指令被解码并准备执行时,Intel和ARM的处理器都使用流水线,就是说解码的过程是并行的。为了更快地执行指令,这些流水线可以被设计成允许指令们不按照程序的顺序被执行(乱序执行)。一些巧逻辑结构可以判断下一条指令是否依赖于当前的指令执行的结果。Intel和ARM都提供乱序执行逻辑结构,由于这结构复杂,直接会导致更多的功耗。
在服务器领域,ARM为追求性能,其功耗优势应该会渐渐消失。 |
|


 再发某公司的PADS格式 PCB封装库全套共享
再发某公司的PADS格式 PCB封装库全套共享 Allegro超强最全模仿PADS快捷键实现Z切换层
Allegro超强最全模仿PADS快捷键实现Z切换层 GL3510 做的USB3.0 HUB PCB和原理图 带3D封
GL3510 做的USB3.0 HUB PCB和原理图 带3D封 altium Designer19使用问题20250115
altium Designer19使用问题20250115 新岸线NL6621M_QFN60 邮票孔物联网模组PCB
新岸线NL6621M_QFN60 邮票孔物联网模组PCB 新岸线NL6621M_QFN60 邮票孔物联网模块模组
新岸线NL6621M_QFN60 邮票孔物联网模块模组 新岸线NL6621M 物联网DEMO PCB 原理图
新岸线NL6621M 物联网DEMO PCB 原理图 allegro羊皮卷
allegro羊皮卷 MS81878运算放大器可P2P兼容OPA188/ADA4077
MS81878运算放大器可P2P兼容OPA188/ADA4077 28款优利德万用表图纸.pdf 电路原理图
28款优利德万用表图纸.pdf 电路原理图 7020开发板
7020开发板 触摸检测IC-VKD233HH SOT23-6L该芯片具有
触摸检测IC-VKD233HH SOT23-6L该芯片具有 超小封装1路触摸/1键触摸触控方案-VKD233HS
超小封装1路触摸/1键触摸触控方案-VKD233HS MS52531数模转换器可兼容AD5541/DAC8831
MS52531数模转换器可兼容AD5541/DAC8831




 发表于 2023-5-8 09:47:32
发表于 2023-5-8 09:47:32






















")
")