TA的每日心情 | 衰
2024-10-6 20:55 |
|---|
签到天数: 1 天 [LV.1]初来乍到
二级逆天
- 积分
- 1392
 
|
马上注册,结交更多好友,享用更多功能,让你轻松玩转社区
您需要 登录 才可以下载或查看,没有账号?立即注册
×
[paragraph]1引言
随着数字通信和工业控制领域的高速发展,要求专用集成电路(ASIC)的功能越来越强,功耗越来越低,生产周期越来越短,这些都对芯片设计提出了巨大的挑战,传统的芯片设计方法已经不能适应复杂的应用需求了。SoC(SystemonaChip)以其高集成度,低功耗等优点越来越受欢迎。开发人员不必从单个逻辑门开始去设计ASIC,而是应用己有IC芯片的功能模块,称为核(core),或知识产权(IP)宏单元进行快速设计,效率大为提高。CPU的IP核是SoC技术的核心,开发出具有自主知识产权的CPUIP核对我国在电子技术方面跟上世界先进的步伐,提高信息产业在世界上的核心竟争力有重大意义。
精简指令集计算机RISC(ReducedInstrucTIonSetComputer)是针对复杂指令集计算机CISC(ComplexInstrucTIonSetComputer)提出的,具备如下特征1)一个有限的简单的指令集;2)强调寄存器的使用或CPU配备大量的能用的寄存器;3)强调对指令流水线的使用。
2CPUIP核的组成
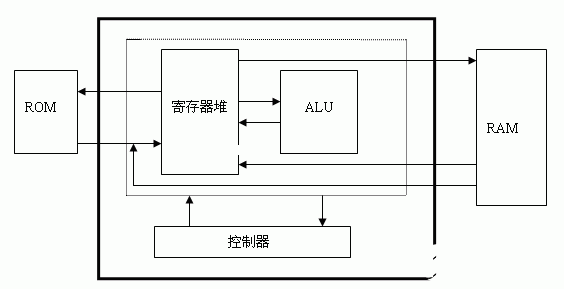
尽管各种CPU的性能指标和结构细节不同,但所要完成的基本功能相同,从整体上可分为八个基本的部件:时钟发生器、指令寄存器、累加器、RISCCPU算术逻辑运算单元、数据控制器、状态控制器、程序控制器、程序计数器、地址多路器。状态控制器负责控制每一个部件之间的相互操作关系,具体的结构和逻辑关系如图1所示。
时钟发生器利用外部时钟信号,经过分频生成一系列时钟信号给CPU中的各个部件使用。为了保证分频后信号的跳变性能,在设计中采用了同步状态机的方法。
指令寄存器在触发时钟clk1的正跳变触发下,将数据总线送来的指令存入寄存器中。数据总线分时复用传递数据和指令,由状态控制器的load_ir信号负责判别。load_ir信号通过使能信号ena口线输入到指令寄存器。复位后,指令寄存器被清为零。每条指令为两个字节16位,高3位是操作码,低13位是地址线。CPU的地址总线为是13位,位寻址空间为8K字节。本设计的数据总线是8位,每条指令取两次,每次由变量state控制。
累加器用于存放当前的运算结果,是双目运算中的一个数据来源。复位后,累加器的值为零。当累加器通过使能信号ena口线收到来自CPU状态控制器load_acc信号后,在clk1时钟正跳沿时就接收来自数据总线的数据。
图1CPU结构图
算术逻辑运算单元根据输入的不同的操作码分别实现相应的加、与、异或、跳转等基本运算。
数据控制器其作用是控制累加器的数据输出,由于数据总线是各种操作传送数据的公共通道,分时复用,有时传输指令,有时要传送数据。其余时候,数据总线应呈高阻态,以允许其他部件使用。所以,任何部件向总线上输出数据时,都需要一个控制信号的,而此控制信号的启、停则由CPU状态控制器输出的各信号控制决定。控制信号datactl_ena决定何时输出累加器中的数据。
地址多路器用于输出的地址是PC(程序计数器)地址还是数据/端口地址。每个指令周期的前4个时钟周期用于从ROM中读取指令,输出的应是PC地址,后4个时钟周期用于对RAM或端口的读写,该地址由指令给出,地址的选择输出信号由时钟信号的8分频信号fecth提供。
程序计数器用于提供指令地址,以便读取指令,指令按地址顺序存放在存储器中,有两种途径可形成指令地址,一是顺序执行程序的情况,二是执行JMP指令后,获得新的指令地址。
3系统时序
RISCCPU的复位和启动操作是通过rst引脚的信号触发执行的,当rst信号一进入高电平,RISCCPU就会结束现行操作,并且只要rst停留在高电平状态,CPU就维持在复位状态,CPU各状态寄存器都设为无效状态。当信号rst回到低电平,接着到来的第一个fetch上升沿将启动RISCCPU开始工作,从ROM的000处的开始读取指令并执行相应的操作。
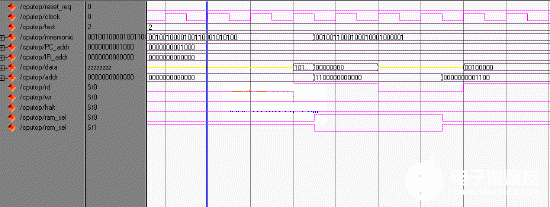
读指令时序,每个指令的前3个时钟周期用于读指令,4“6周期读信号rd有效,第7个周期读信号无效,第8个周期地址总线输出PC地址,为下一个指令作准备。
写指令时序,每个指令的第3.5个时钟周期建立写地址,第四个周期输出数据,第5个时钟周期输出写信号,第6个时钟结束,第7.5个时钟周期输出为PC地址,为下个指令做准备。
如图2所示,这是ModelSimSE6.0进行波形仿真的结果。
4微处理器指令
数据处理指令:数据处理指令完成寄存器中数据的算术和逻辑操作,其他指令只是传送数据和控制程序执行的顺序.因此,数据处理指令是唯一可以修改数据值的指令,数据处理指令一般需两个源操作数,产生单个结果.所有的操作数都是8位宽,或者来自寄存器,或者来自指令中定义的立即数.每一个源操作数寄存器和结果寄存器都在指令中独立的指定。
图2读写指令时序
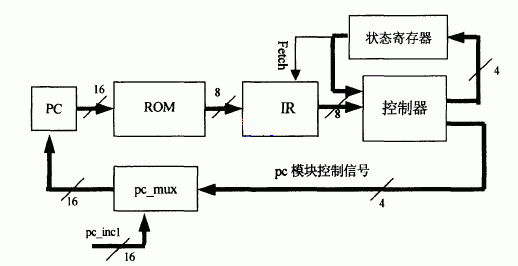
数据传送和控制转移类指令:共有17条,不包括按布尔变量控制程序转移的指令。其中有全存储空间的长调用、长转移和按2KB分块的程序空间内的绝对调用和绝对转移;全空间的长度相对转移及一页范围内的短相对转移;还有条件转移指令。这类指令用到的助记符有ACALL,AJMP,LCALL,LJMP,SJMP,M,JZ,JNZ,ONE,DJNZ。控制转移类指令主要用来修改1x指针从而达到对程序流的控制,所用到的寄存器主要有sp,pc,ir等寄存器。指令由操作码和操作数组成,取指令电路的目的就是把指令码和操作数分开。组成电路由如图3所示。取指令电路由程序指针,程序指针解析模块、ROM,IR(指令寄存器),控制器状态寄存器组成。取指令指令的过程如下:PC指针的值经过pc_mux模块赋值,把ROM中的指令取出来,送到指令寄存器的数据输入口。指令寄存器受状态寄存器的控制,当取指令信号有效时,ROM中的指令码被保存在指令寄存器中,然后经控制器译码,产生控制信号,对PC指针的增量加以控制取出下一条指令。
图3取指令电路
5汇编
汇编程序是为了调试软核而开发的,手工编写机器码很容易出错并且工作量很大。在调试过程中修改指令集时,汇编程序也要作相应的修改。所以要求编译器的结构简单性能可靠,在程序中必要的地方可以用堆叠代码方法实现,不必考虑编程技巧和汇编器效率问题。汇编程序用于测试RISCCPU的基本指令集,如果CPU的各条指令执行正确,停止在HLT指令处。如果程序在其它地址暂停运行,则有一个指令出错。程序中,@符号后的十六进制表示存储器的地址,每行的//后表示注释。下面是一小段程序代码,编译好的汇编机器代码装入虚拟ROM,要参加运算的数据装入虚拟RAM就可以开始进行仿真。
机器码地址汇编助记符注释
@00//地址声明
101_11000//00BEGIN:LDADATA_2
0000_0001
011_11000//02ANDDATA_3
0000_0010
100_11000//04XORDATA_2
0000_0001001_00000//06SKZ
0000_0000
000_00000//08HLT//ANDdoes‘twork
6调试
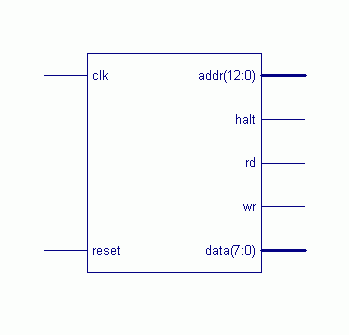
最基本的调试手段是基于FPGA厂商提供的开发和仿真环境,用硬件描述语言编写TESTBENCH,构成一个最小运行环境。TESTBENCH产生对目标软核的激励,同时记录软核的输出,和预期值进行比对,可以确定核的设计错误。这种方法的好处是实现容易,结果准确,但硬件描述语言编码量较大。为了仿真结果的准确性,无论功能仿真还是时序仿真,仿真的步长都不能太小,结果导致整个系统仿真时间太长。本设计中先对RISCCPU的各个子模块进行了分别综合,检查正确性,如果发现错误可以在较小的范围内来检查并验证。子模块综合完毕后,把要综合的RISCCPU的模块与外围器件以及测试模块分离出来组成一个大模块,综合后的的RISCCPU模块如图4所示,这是XilinxISE7.1所综合生成的技术原理图。
综合的结果只是通用的门级网表,只是一些与、或、非门的逻辑关系,和芯片实际的配置情况还有差距。此时应该使用FPGA/CPLD厂商提供的实现与布局布线工具,根据所选芯片的型号,进行芯片内部功能单元的实际连接与映射。这种实现与布局布线工具一般要选用所选器件的生产商开发的工具,因为只有生产者最了解器件内部的结构,如在ISE的集成环境中完成实现与布局布线的工具是FlowEngine。
图4CPU技术原理图
STA(StaTIcTImingAnalysis)静态时序分析,完成FPGA设计时必须的一个步骤。在FPGA加约束、综合、布局布线后,在ISE中可以运行TimingAnalyzer生成详细的时序报告,本设计中Minimumperiod:12.032ns(MaximumFrequency:83.112MHz),Minimuminputarrivaltimebeforeclock:6.479ns,Maximumoutputrequiredtimeafterclock:9.767ns。然后,设计人员检查时序报告,根据工具的提示找出不满足Setup/Holdtime的路径,以及不符合约束的路径,进行修改保证数据能被正确的采样。在后仿真中将布局布线的时延反标到设计中去,使仿真既包含门延时,又包含线延时信息。这种后仿真是最准确的仿真,能真实地反映芯片的实际工作情况。
7结论
复杂的RISCCPU设计是一个从抽象到具体的过程,本文根据FPGA的结构特点,围绕在FPGA上设计实现八位微处理器软核设计方法进行探讨,研究了片上系统的设计方法和设计复用技术,并给出了指令集和其调试方法,提出了一种基于FPGA的微处理器的IP的设计方法。本文作者创新点是:根据SpartanII的内部结构,在编码阶段实现了地址和数据的优化,实现阶段对内部布局布线进行重新配置,设计实现的微处理器仅占用78个slices,1个BlockRAM,在10万门的芯片实现,占用6%的资源。
责任编辑:gt |
|

 再发某公司的PADS格式 PCB封装库全套共享
再发某公司的PADS格式 PCB封装库全套共享 Allegro超强最全模仿PADS快捷键实现Z切换层
Allegro超强最全模仿PADS快捷键实现Z切换层 SHT3x /SHT2x RS485
SHT3x /SHT2x RS485 J-Link V9 AD USB Type-C
J-Link V9 AD USB Type-C FE1.1s USB Hub*4
FE1.1s USB Hub*4 英伟达GPU模组-middleplane模组-18层板
英伟达GPU模组-middleplane模组-18层板 基于STM32智能鱼缸控制系统
基于STM32智能鱼缸控制系统 allegro羊皮卷
allegro羊皮卷 systrace工具使用
systrace工具使用 龙迅LT7911UXC+RTS5880 做的VR眼镜 方案原
龙迅LT7911UXC+RTS5880 做的VR眼镜 方案原 玩具触摸芯片/18按键触摸感应IC/高抗干扰触
玩具触摸芯片/18按键触摸感应IC/高抗干扰触 抗噪液晶屏驱动/抗干扰液晶驱动芯片/LCD显
抗噪液晶屏驱动/抗干扰液晶驱动芯片/LCD显 矢量网络分析仪的技术原理和应用场景
矢量网络分析仪的技术原理和应用场景 射频微电子学 原书第2版 精编版,(美)毕查
射频微电子学 原书第2版 精编版,(美)毕查

 发表于 2020-10-30 09:03:40
发表于 2020-10-30 09:03:40





















")
")