马上注册,结交更多好友,享用更多功能,让你轻松玩转社区
您需要 登录 才可以下载或查看,没有账号?立即注册
×
2020年12月15日,在GTC中国大会上,NVIDIA首席科学家,NVIDIA研究院高级副总裁BillDally分享了团队正在研发的技术。
Ampere技术在高性能计算方面有着卓越成效
“我们打造了性能非凡的高性能计算设备,致力于解决世界上极为苛刻的计算问题,所有这一切的基础都是硬件。”Bill Dally说。
图:NVIDIA首席科学家,NVIDIA研究院高级副总裁Bill Dally Bill Dally首先介绍了Ampere,他说:“AmpereA100SXM模块具有处理海量计算的性能,借助这一模块,可以扩展Ampere的功能,从而解决非常苛刻的计算问题。”
并且如果用户还想扩展,可以取8个这样的是Ampere,将其放入DGX机箱中,Bill Dally说:“我们可以在机架中安装多个DGX机箱与Mellanox交换机,打造世界上性能最强大的计算机。”
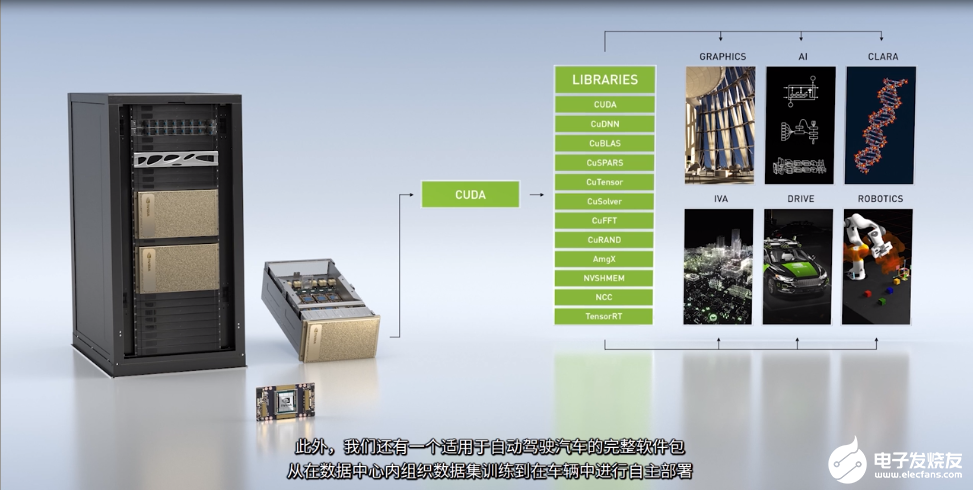
硬件本身并不能解决世界上的难题,还需要借助软件来集中这种强大的计算能力应对苛刻的问题,BillDally表示,为了实现这一目标,NVIDIA投入了大量的精力来开发软件套件。
NVIDIA很早推出了CUDA,自2006年以来,人们一直使用CUDA来充分利用GPU的功能,为了方便人们在CUDA上构建应用程序,NVIDIA还提供了一整套开发库。
NVIDIA有大量的软件可以用来支持人工智能,包括用于自然语音处理和推荐系统的软件。
在医疗健康领域,NVIDIA推出了Clare软件包,它应用广泛,从Parabricks基因组测序分析到图像分析,再到挖掘医学论文数据库等,都可以使用。NVIDIA还提供了应用于智能视频分析的软件包,可以用来获取视频流,并根据所见得出结论。此外,NVIDIA还有一个适用于自动驾驶汽车的完整软件包,从在数据中心内组织数据集训练到车辆中进行自主部署。
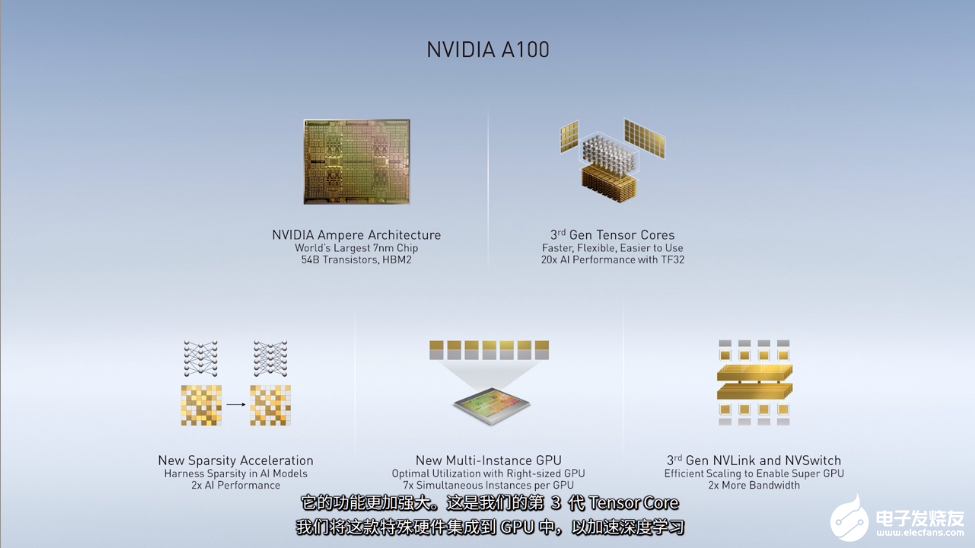
NVIDIA A100采用7nm芯片,具有540亿个晶体管,而且还具有许多创新功能,相比上一代产品,它的功能更加强大。Bill Dally说:“这是NVIDIA第3代TensorCore,我们将这款特殊硬件集成到GPU中,以加速深度学习,在这一代核心中,我们增加了对新数据类型的支持TensorFLOAT32,解决了曾经在BFLOAT16和FP16之间进行数据类型选择的问题。”
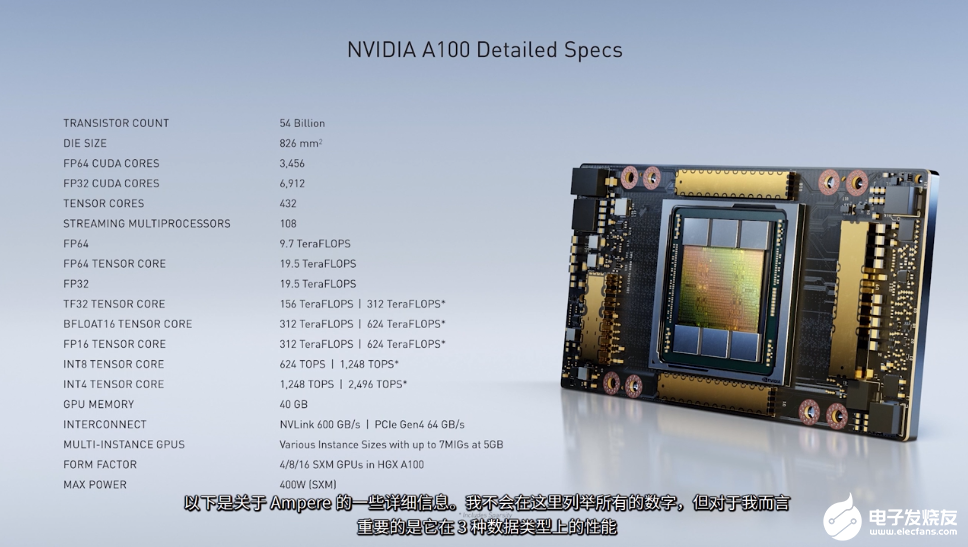
Ampere的详细信息 NVIDIA A100的性能能达到1.5倍,在深度学习架构中,这是一个巨大飞跃,Bill Dally表示:我们使用这些A100,并将8个A100与大量SSD存储、大量RAM和9个Mellanox ConnectX-6 NIC组装在一起构建一台设备,这将组成一个性能出众的计算平台,该平台的性能将是其中一个GPU的8倍。
Ampere技术不仅在于其在深度学习方面表现出色,还在于它在高性能计算方面也有着卓著成效,而且还简化了AI与科学应用的结合。
NVIDIA研究院正在研究的项目
接着,Bill Dally通过NVIDIA研究院正在研究的项目,阐述了自己带领的200人的研究团队如何成功实现“黄氏定律(Huang’s Law)”。
这则定律以NVIDIA首席执行官黄仁勋(Jensen Huang)名字命名,预测GPU将推动AI性能实现逐年翻倍。Bill Dally说:“如果我们真想提高计算机性能,黄氏定律就是一项重要指标,且在可预见的未来都将一直适用。”
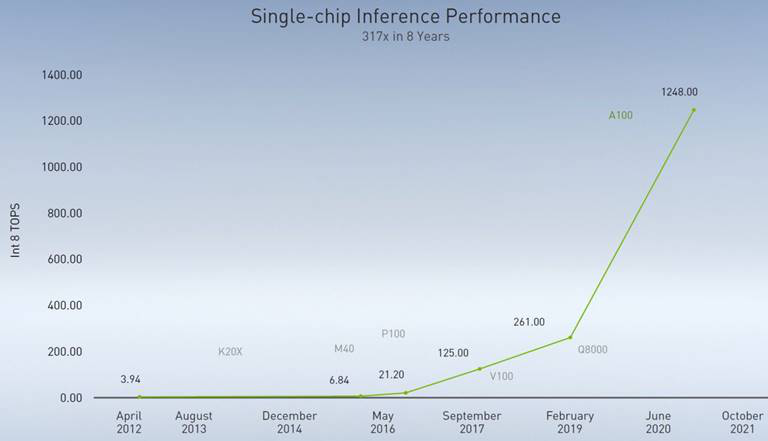
NVIDIA助力AI推理性能每年提升一倍以上 为实现这一突破,NVIDIA研究人员专门开发了一种名为MAGNet的工具,其生成的AI推理加速器在模拟测试中,能够达到每瓦100teraops的推理能力,比目前的商用芯片高出一个数量级。
MAGNet采用了一系列新技术来协调并控制通过设备的信息流,最大限度地减少数据传输,而数据传输正是当今芯片中最耗能的环节。这一研究原型以模组化实现,因此能够灵活扩展。
另外,研究团队还开展了一项研究,旨在以更快速的光链路取代现有系统内的电气链路。
Bill Dally拥有120多项专利,在2009年加入NVIDIA之前,曾任斯坦福大学计算机科学系主任。Bill Dally表示:“我们可以将连接GPU的NVLink速度提高一倍,也许还会再翻番,但电子信号最终会消耗殆尽。”
该团队正在与哥伦比亚大学的研究人员密切合作,探讨如何利用电信供应商在其核心网络中所采用的技术,通过一条光纤来传输数十路信号。
这种名为“密集波分复用”的技术,有望在仅一毫米大小的芯片上实现Tb/s级数据的传输,是如今互连密度的十倍以上。
除了更大的吞吐量,光链路也有助于打造更为密集型的系统。Dally举例展示了一个未来将搭载160多个GPU的NVIDIA DGX系统模型。
工程师借助光链路,在单一系统中可搭载160多个GPU 软件方面,NVIDIA的研究人员开发了全新编程系统原型Legate。开发者借助Legate,即可在任何规模的系统上,运行针对单一GPU编写的程序——甚至适用于诸如Selene等搭载数千个GPU的巨型超级计算机。
Legate将一种新的编程速记融入了加速软件库和高级运行时环境Legion,目前它正在美国国家实验室接受测试。
中国市场对NVIDIA至关重要
在探讨“NVIDIA科技助推中国产业创新”这个话题的时候,NVIDIA全球业务运营执行副总裁JAY PURI谈到,中国应用AI为行业提供竞争优势的能力一直处于最前沿,世界上一些极为重要的AI研究人员都在中国,创业生态系统充满活力,NVIDIA在中国进行了大量投资,中国市场对NVIDIA至关重要。 | 
 再发某公司的PADS格式 PCB封装库全套共享
再发某公司的PADS格式 PCB封装库全套共享 Allegro超强最全模仿PADS快捷键实现Z切换层
Allegro超强最全模仿PADS快捷键实现Z切换层 SHT3x /SHT2x RS485
SHT3x /SHT2x RS485 J-Link V9 AD USB Type-C
J-Link V9 AD USB Type-C FE1.1s USB Hub*4
FE1.1s USB Hub*4 英伟达GPU模组-middleplane模组-18层板
英伟达GPU模组-middleplane模组-18层板 基于STM32智能鱼缸控制系统
基于STM32智能鱼缸控制系统 allegro羊皮卷
allegro羊皮卷 systrace工具使用
systrace工具使用 龙迅LT7911UXC+RTS5880 做的VR眼镜 方案原
龙迅LT7911UXC+RTS5880 做的VR眼镜 方案原 玩具触摸芯片/18按键触摸感应IC/高抗干扰触
玩具触摸芯片/18按键触摸感应IC/高抗干扰触 抗噪液晶屏驱动/抗干扰液晶驱动芯片/LCD显
抗噪液晶屏驱动/抗干扰液晶驱动芯片/LCD显 矢量网络分析仪的技术原理和应用场景
矢量网络分析仪的技术原理和应用场景 射频微电子学 原书第2版 精编版,(美)毕查
射频微电子学 原书第2版 精编版,(美)毕查




 发表于 2020-12-16 09:11:05
发表于 2020-12-16 09:11:05










 只卖矿工
只卖矿工




")
")